
Learning Problem-agnostic Speech Representations from Multiple Self-supervised Tasks
Learning Problem-agnostic Speech Representations from Multiple Self-supervised Tasks(2019) 논문의 Abstract
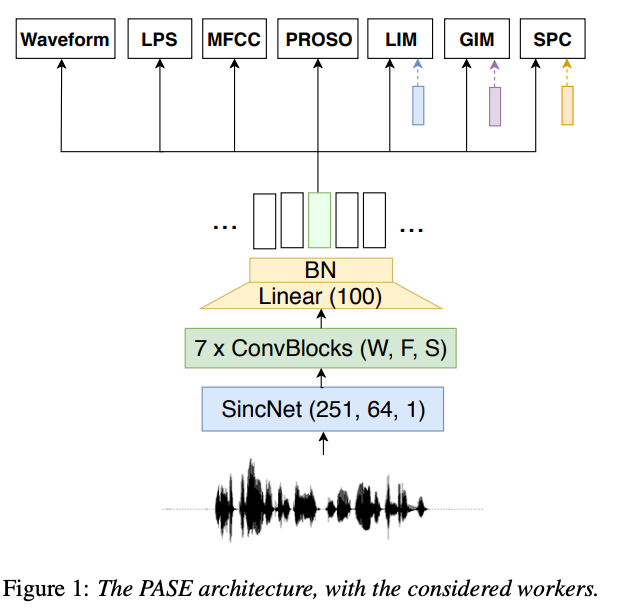
Architecture
Abstract
이 논문은 자기지도 학습을 사용하여 음성 신호의 표현을 학습하는 새로운 방법을 제안.
이 방법은 단일 신경망 인코더 뒤에 여러 작업을 수행하는 다수의 워커를 두어 다양한 자기지도 작업을 공동으로 해결.
다양한 작업 간의 합의는 인코더에 유의미한 제약을 부과하여 일반적인 표현을 발견하고 피상적인 특징을 학습하는 위험을 최소화하는 데 기여.
실험을 통해 이 방법이 transfer 가능하고, robust하며, 일반화 된 특징을 학습.
이 특징들은 화자의 정체성, 음소, 감정적 단서와 같은 더 높은 수준의 특징까지 음성 신호에서 관련 정보를 담고 있음.
인코더 아키텍쳐를 사용하여 다른 Task에 직접 사용하거나 적응시키기 쉽다.
Introduction
전통적인 지도 학습 방식은 큰 어노테이션 데이터에 의존하고, 특정 문제에 편향된 표현을 학습하는 경향이 있어, 다른 문제에 적용하기 어려운 한계가 있다.
unsupervised learning은 레이블이 없는 데이터로부터 지식을 추출하여 이러한 문제를 완화할 수 있으며, 대표적인 방법으로는 Deep-Auto Encoder 와 Restricted Boltzmann machines 이 있다.
self supervised learning은 데이터 자체에서 타겟을 생성하고, 컴퓨터 비전 분야에서 인기를 얻고 있으며, 오디오 표현 학습에도 확장되고 있음.
음성 신호는 고차원적이고 긴 시퀀스의 복잡한 계층 구조를 가지고 있어, 의미 있는 표현을 학습하기 위한 자기 지도 학습 과제를 찾기 어려움.
이를 해결하기 위해, 다중 자기 지도 학습 과제를 수행하는 신경망 앙상블을 제안하여, 다양한 관점에서 음성 표현을 학습.
제안된 ‘PASE’는 원시 음성 파형에서 robust한 표현을 발견하고, 다양한 음성 분류 작업에서 전통적인 수작업 특징보다 우수한 성능을 보임.

Comments