
Speech and speaker recognition from raw waveform with sincnet
Speech and speaker recognition from raw waveform with sincnet(2018) 논문의 Abstract
Abstract
2018년 기준 최신 SOTA는 이전 SOTA인 GMM-UBMs (가우시안 혼합 모델-범용 백그라운드 모델)보다 더 나은 성능을 보인 음성 segment인 i-vector*에 기반을 두고 있음.
SincNet은 기존의 i-vector 방식 대신 원시 음성 샘플을 직접 입력으로 사용하는 CNN을 통해 화자 인식 분야에서 뛰어난 결과를 보여주는 새로운 CNN 아키텍처.
이 아키텍처는 표준 CNN과 달리 모든 필터 요소를 학습하는 대신, 데이터로부터 직접 저주파와 고주파 컷오프 주파수만을 학습하여 맞춤형 밴드패스 필터를 구현.
SincNet은 화자 식별 및 검증 작업에서 표준 CNN보다 빠르게 수렴하며 더 나은 성능을 보여주는 것으로 실험을 통해 입증.
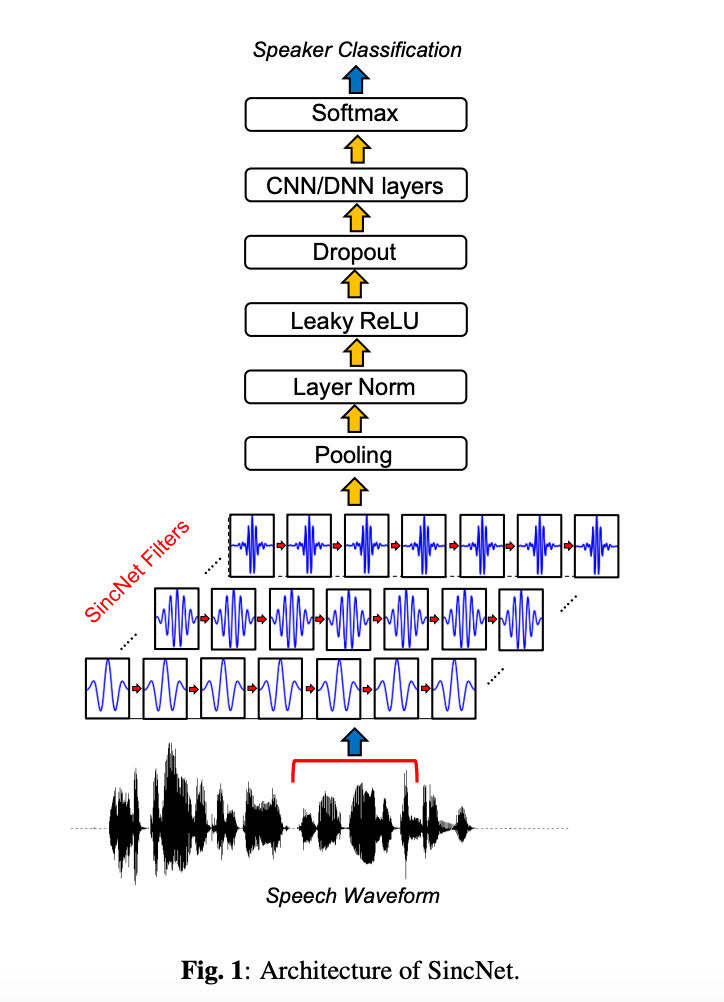
Introduction
SincNet는 전통적인 CNN과 다르게, 원시 음성 파형에 직접 적용되는 매개변수화된 sinc 함수를 이용한 밴드패스 필터를 사용하여 음성 신호의 보다 의미 있는 특징을 추출하는 새로운 아키텍처를 제안.
실험 결과, 제한된 훈련 데이터와 짧은 테스트 문장을 사용하는 현실적인 조건 하에서 SincNet은 전통적인 CNN보다 빠르게 수렴하며, 최종적인 음성 인식 과제에서 더 나은 성능을 달성.
SincNet 아키텍처는 또한 i-vector 기반의 전통적인 음성 인식 시스템보다 우수한 성능을 보여주며, 이는 특히 첫 번째 컨볼루션 계층에서 더 효율적인 음성 신호 표현을 가능하게 하는 필터 형태에 대한 제약을 추가함으로써 달성.

Comments