
Automatic Speech Recognition
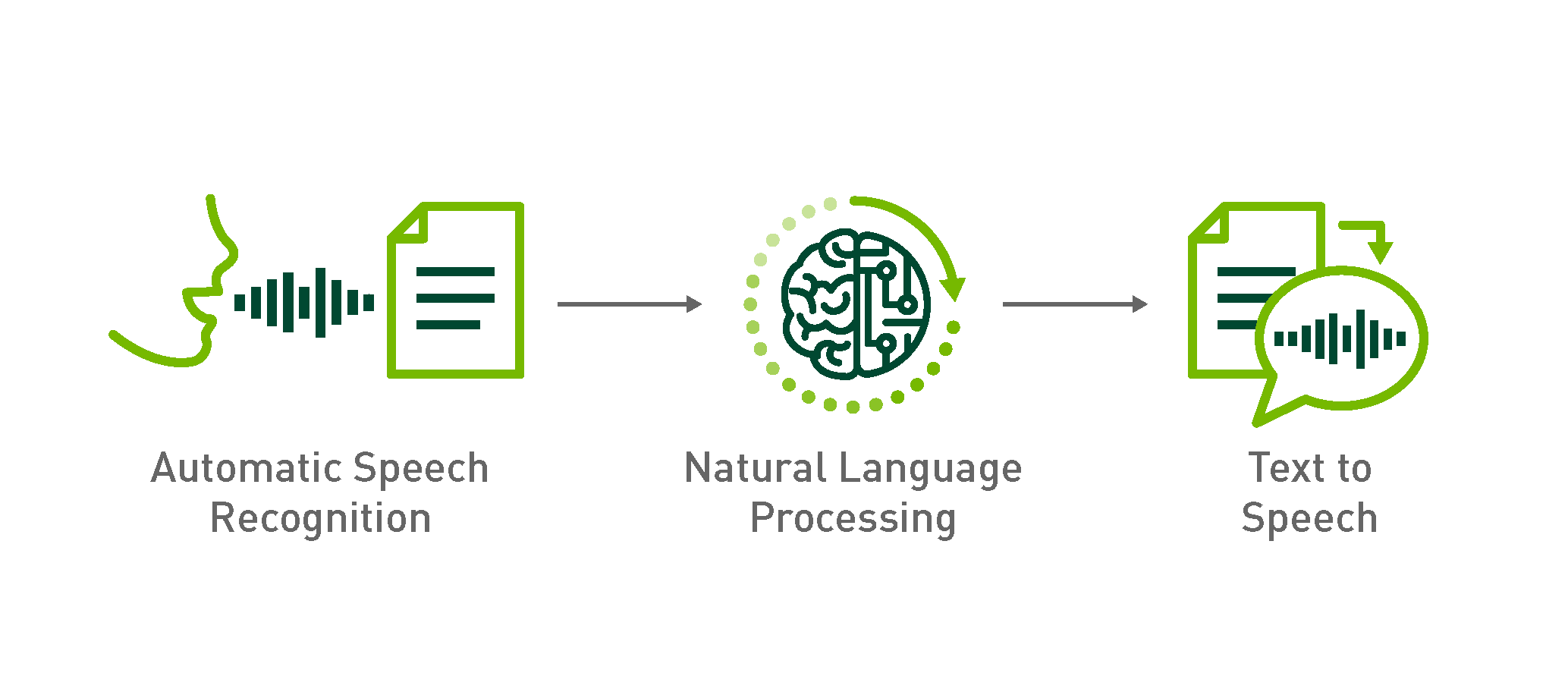
Overview
ratsgo’s speech book 를 보고 재작성
Definition
자동 음성 인식(Automatic Speech Recognition)이란 음성 신호(acoustic signal)를 단어(word) 혹은 음소(phoneme) 시퀀스로 변환하는 시스템
Phoneme
음소란 언어의 소리 체계 내에서 다른 소리와 구별되어 대립적 기능을 하는, 언어 사용자가 인식하는 소리의 최소 단위.
예를 들어 한국어에서 ‘물’, ‘불’, ‘풀’, ‘뿔’은 초성 ㅁ, ㅂ, ㅍ, ㅃ 에 의해 의미가 구별되기 때문에, /ㅁ/, /ㅂ/, /ㅍ/, /ㅃ/은 한국어에서 각자 다른 음소
Problem Setting
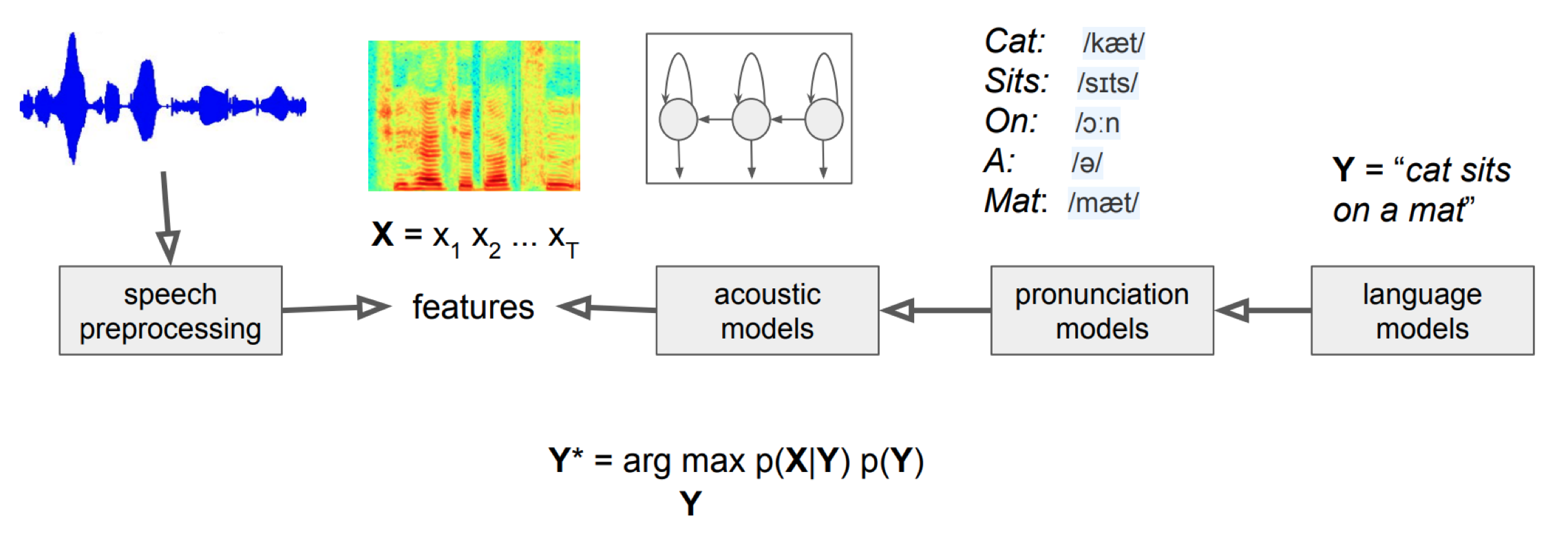
자동 음성 인식 모델은 입력 음성 신호 X(x1,x2,…,xt)에 대해 가장 그럴듯한(likely) 음소/단어 시퀀스 Y( y1,y2,…,yn)를 추정 따라서 자동 음성 인식 모델의 목표는 P(Y|X)를 최대화하는 음소/단어 시퀀스 Y의 추론(inference)
식으로 나타내면 아래와 같다.
\[\hat{Y} = \underset{Y}{\mathrm{argmax}} \ P(Y|X)\]같은 음소나 단어라 하더라도 사람마다 발음하는 양상이 다르고 화자가 남성이냐 여성이냐에 따라서도 음성 신호는 달라질 수 있다. 따라서 불확실성 하에서 의사결정문제를 수학적으로 다룰 때 중요하게 이용되는 베이즈 정리(Bayes’ Theorem)로 이를 표현한다.
\[\hat{Y} = \arg\max_Y P(X|Y)P(Y)P(X)\]P(X)는 베이즈 정리에서 evidence. evidence는 Y의 모든 경우의 수에 해당하는 X의 발생 확률이라 구하기 어렵다.
하지만 이때 $P(X)$는 모든 $Y$에 대해 동일하고, 우리의 문제는 최대의 Y를 내놓는 것이기 때문에 $P(X)$를 생략할 수 있다.
따라서 아래와 같이 수식을 정리할 수 있다.
\[\hat{Y} = \arg\max_Y P(X|Y)P(Y)\]음성 인식 모델은 크게 두 가지 컴포넌트로 구성된다. 우변의 첫번째 항 $P(X|Y)$ 는 음향 모델(Acoustic Model) $P(Y)$는 언어 모델(Language Model)로 불린다. 음향 모델은 ‘음소/단어 시퀀스’와 ‘입력 음성 신호’가 어느 정도 관계를 맺고 있는지 추출하고, 언어 모델은 해당 음소/단어 시퀀스가 얼마나 자연스러운지 확률값 형태로 나타낸다.
Architecture
Acoustic Model
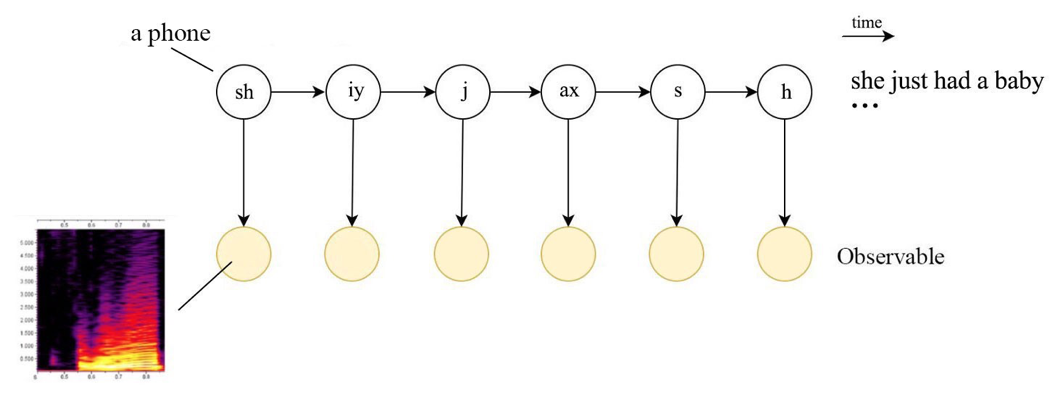
음향 모델은 히든 마코프 모델(Hidden Markov Model, HMM)과 가우시안 믹스처 모델(Gaussian Mixture Model, GMM) 조합이 자주 쓰였다.
Hidden Markov Model
히든 마코프 모델(Hidden Markov Model, HMM)은 각 상태가 마코프체인을 따르되 은닉(hidden)되어 있다고 가정.
마코프체인의 의미는 상태(state)의 확률은 단지 그 이전 상태에만 의존한다는 것.
즉 한 상태에서 다른 상태로의 전이(transition)는 그동안 상태 전이에 대한 긴 이력(history)을 필요로 하지 않고 바로 직전 상태에서의 전이로 추정할 수 있다.
결국 HMM은 상태가 마코프체인을 따르되 은닉(hidden)되어 있다고 가정한다.
HMM 을 사용하는 예시는 아래와 같다.
예컨대 당신이 100년 전 기후를 연구하는 학자인데, 주어진 정보는 당시 아이스크림 소비 기록뿐이라고 칩시다.
이 정보만으로 당시 날씨가 더웠는지, 추웠는지, 따뜻했는지를 알고 싶은 겁니다.
우리는 아이스크림 소비 기록의 연쇄를 관찰할 수 있지만, 해당 날짜의 날씨가 무엇인지는 직접적으로 관측하기 어렵습니다.
HMM 이처럼 관측치 뒤에 은닉되어 있는 상태(state)를 추정하고자 할 때 사용할 수 있다.
\[P(q_i | q_1, \ldots, q_{i-1}) = P(q_i | q_{i-1})\]최대 likely 를 구하는 것이 목표이며 Training 은 EM Algorithm 을 사용한다.
Gaussian Mixture Model
Gaussian Mixture Model (GMM)은 이름 그대로 가우시안 분포 (정규분포)를 여러개 혼합하여 데이터의 복잡한 분포를 근사하기 위한 머신러닝 알고리즘
\[\begin{equation} p(\textbf{x}) = \sum_{k=1}^K \pi_k \mathcal{N}(\textbf{x} ; \boldsymbol{\mu}_k, \Sigma_k) \label{eq:gmm}\end{equation}\]마찬가지로 최대 likely 를 구하는 것이 목표이며 Training 은 EM Algorithm 을 사용한다.
Language Model
언어 모델(Language Model)은 음소(또는 단어) 시퀀스에 대한 확률 분포(a probability distribution over sequences of words)를 반환. 다시 쓰면 음소(또는 단어) 시퀀스 Y가 얼마나 그럴듯한지(likely)에 관한 P(Y)를 반환.
기존에는 자동 음성 인식 모델에서 언어 모델은 통계 기반 n-gram 모델이 자주 쓰였으나, 최근에는 Deep Learning 을 이용한 $P(Y|X)$를 바로 추정하는 End to End 모델을 사용한다.
Acoustic Features
음향의 특징을 추출하기 위한 방법
Using Rule base
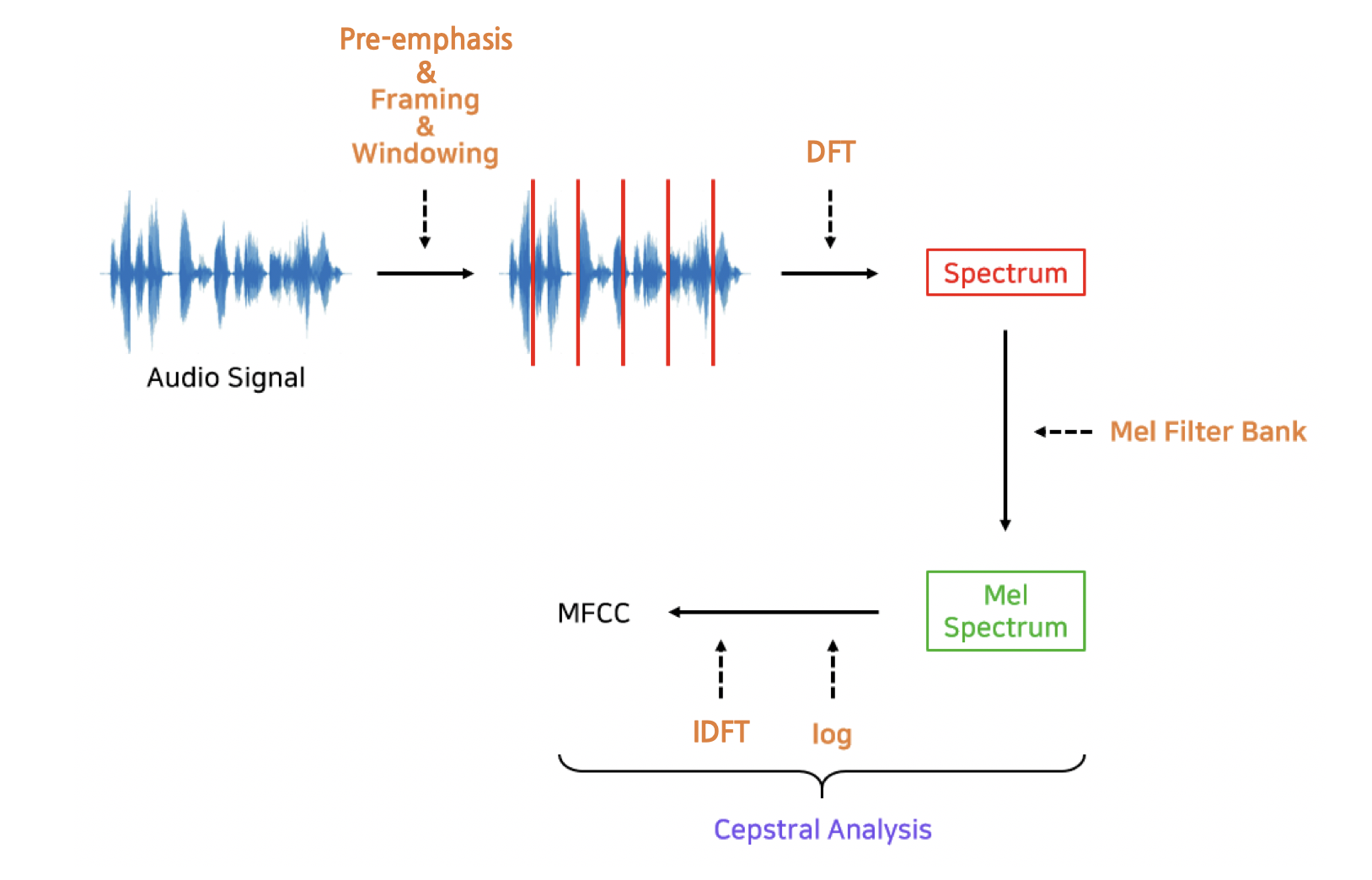
‘HMM+GMM’이 사용하는 음향 특징(Acoustic Feture)은 MFCCs(Mel-Frequency Cepstral Coefficients)이다.
사람이 잘 인식하는 말소리 특성을 부각시키고 그렇지 않은 특성은 생략하거나 감소시킨 룰(rule)에 기반한 피처(feature)
Using Deeplearning
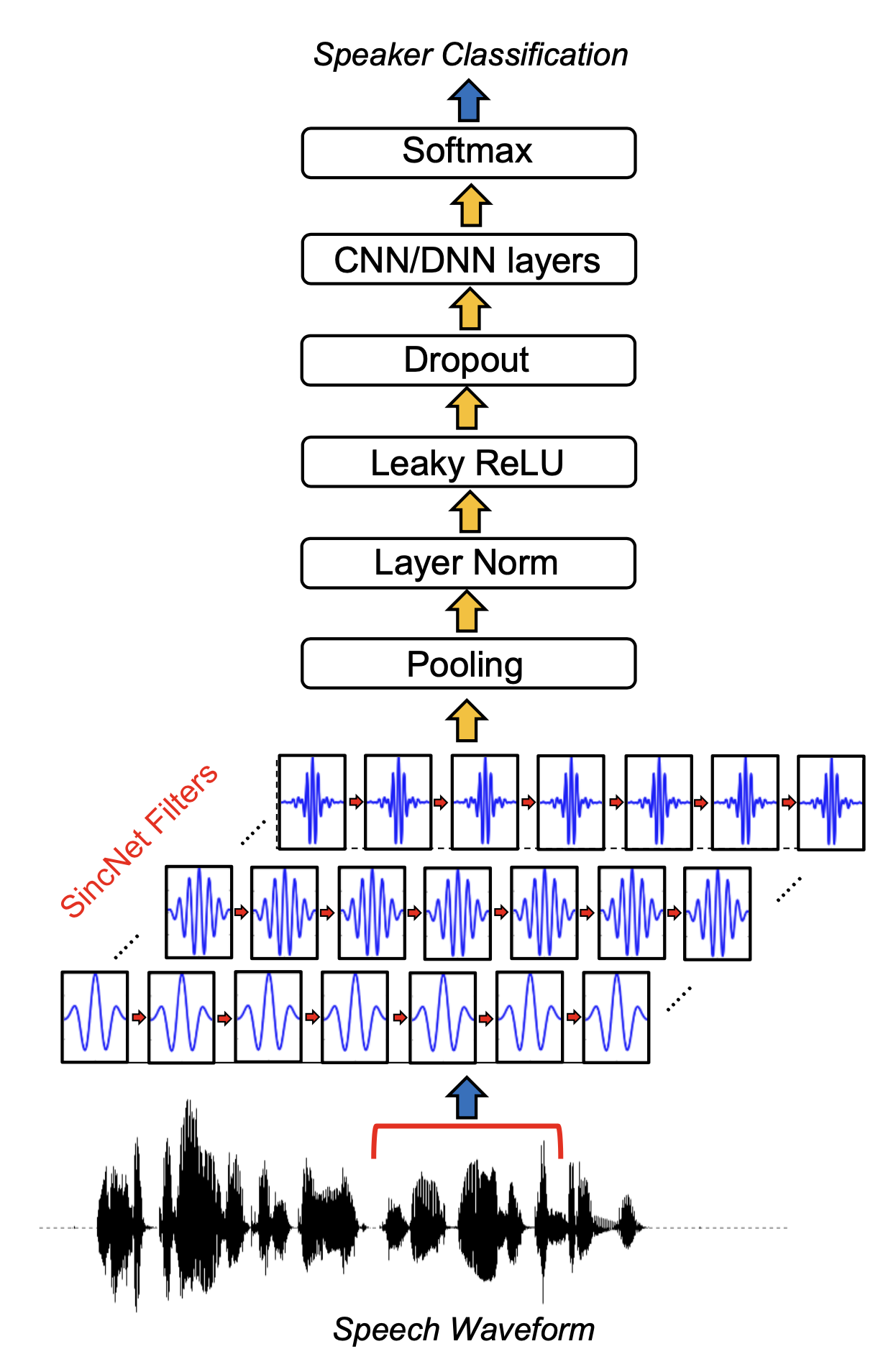
딥러닝 기반 특징 추출 방법인 SincNet. 문제 해결에 도움이 되는 주파수 영역대를 부각시키고 나머지는 버린다.
룰 기반 피처인 MFCC와 달리 딥러닝 기반 음향 특징 추출 기법들은 그 과정이 결정적(deterministic)이지 않고 확률적(probabilistic)
Reference
ratsgo’s speech book. ratsgo’s HMMs 가우시안 혼합 모델 (Gaussian Mixture Model, GMM)과 EM 알고리즘

Comments