
Acoustic Phonetics
Overview
ratsgo’s speech book 를 보고 재작성
Phonetics
음성학은 인간이 말을 할 때 이용하는 소리를 물리적으로 분석
- 조음음성학 : 말소리를 만들어 내기 위해 우리 몸의 기관이 어떤 모양으로 움직이는가를 연구.
- 음향음성학 : 말소리의 음파를 분석하고 연구.
- 청취음성학 : 말소리를 인지하는 과정에 대한 연구 분야. 말소리가 귀를 통과하는 과정과 뇌에서 그것을 해석하는 과정을 연구.
Phonology
음운론은 말소리의 물리적 실체를 직접 다루지 않고, 언어 사용자의 머릿속에 있는 말소리에 대한 지식을 체계적으로 기술하고 설명하는 분야
심리적이고 추상적이며 최소 단위인 음운의 설정, 음운들 사이의 관계를 파악하는 음운 체계의 확립, 의미를 가지고 있는 최소 단위인 형태소들이 결합할 때 일어나는 음운 변동의 문제 등에 집중
음운이란? 뜻을 구별해 주는 최소의 소리 단위, 음운은 음소와 운소를 합친 개념
음소는 의미 분화를 일으키는 최소의 단위이고, 운소는 소리의 길이, 높낮이, 세기 등의 말의 뜻을 분화하는 기능
Acoustic Phonetics
Wave
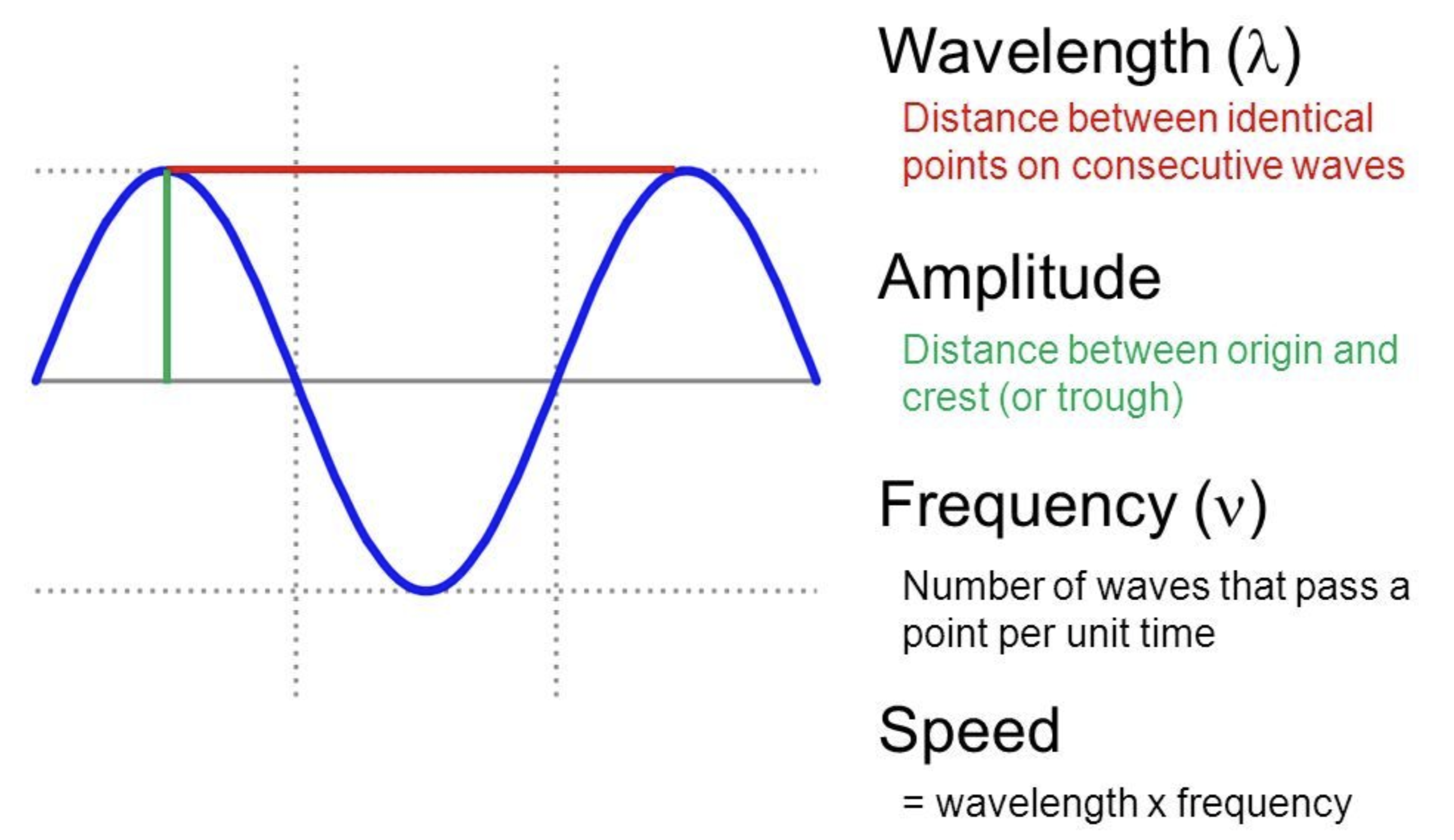
푸리에 정리(Fourier Theorem)에 따르면 아무리 복잡해보이는 웨이브도 삼각함수인 사인(sine)이나 코사인(cosine)의 합으로 나타낼 수 있다.
- 진폭은 웨이브의 최대 높이를, 사이클은 웨이브 패턴의 한 번 반복을 의미.
- 주기는 한 사이클이 완료되는 데 필요한 시간, 주파수는 단위 시간당 사이클 수.
- 주기(T)와 주파수(f)는 역수 관계에 있으며, 주파수는 헤르츠(Hz)로 표현.
Digitization
- 음성 신호는 샘플링을 통해 연속적인 아날로그 신호에서 이산적인 디지털 신호로 변환되며, 샘플링 레이트는 1초당 샘플의 개수를 나타냄(예: 44.1KHz는 1초에 44100개의 샘플).
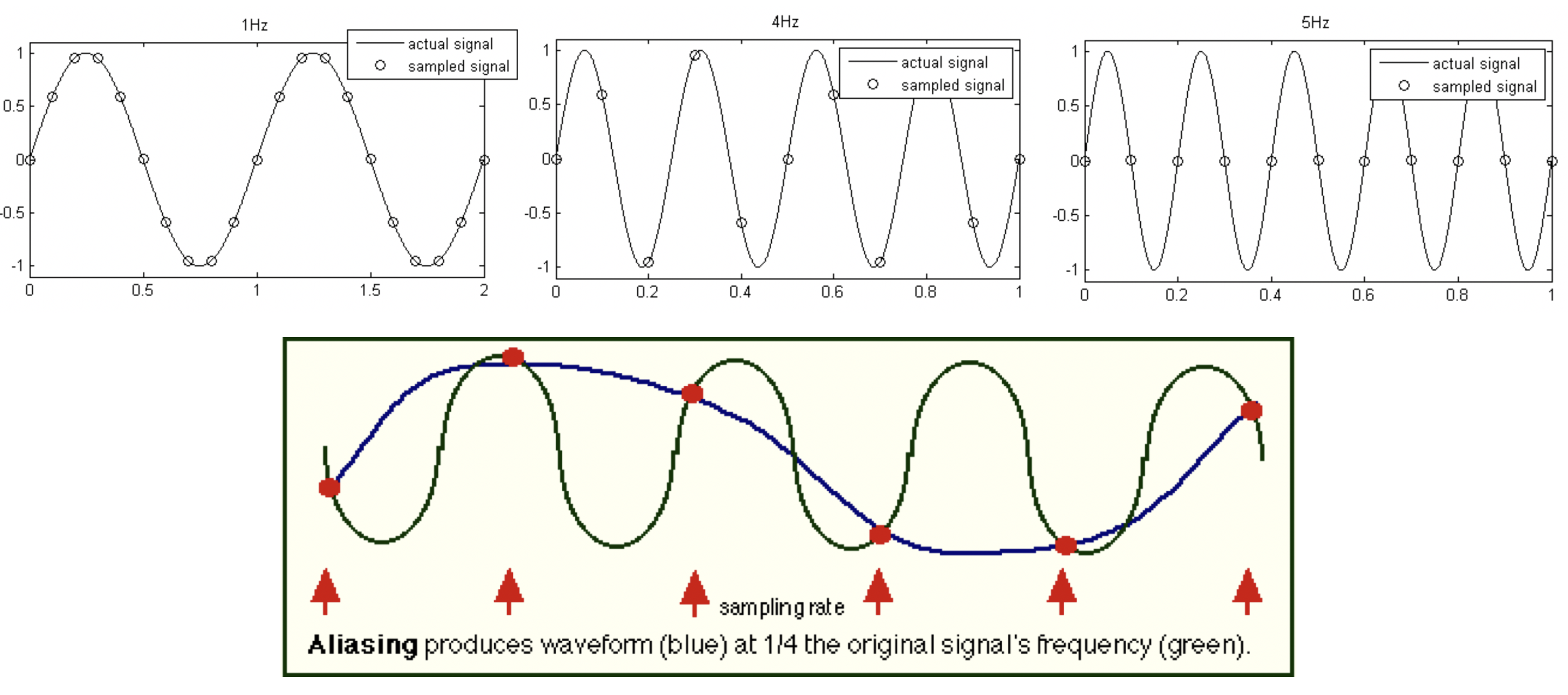
- 나이퀴스트 정리에 따르면 원래 신호의 최대 주파수의 2배 이상의 샘플링 레이트로 샘플링하면 원 신호를 충분히 재생할 수 있다.
- 인간의 가청 주파수 범위는 20~20000Hz이므로, 40000Hz 이상의 샘플링 레이트를 사용하면 인간이 들을 수 있는 거의 모든 소리를 디지털로 복원할 수 있다.
Anti-Aliasing
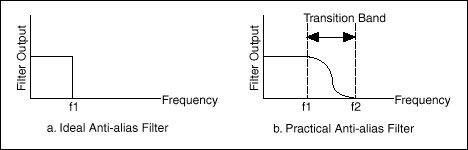
- Anti-aliasing 필터는 샘플링 전에 아날로그 신호에 적용되어 나이퀴스트 주파수보다 높은 주파수 성분을 제거함으로써 샘플링에 의한 왜곡(aliasing)을 방지.
- 이상적인 bandpass 필터는 주파수 도메인에서 사각형이지만, 현실에서는 시간 도메인의 길이 제한으로 인해 transition band를 가진 필터 모양을 사용.
- CD 음질의 샘플링 레이트가 44.1KHz인 이유는 인간의 가청 주파수 범위와 나이퀴스트 정리를 고려하고, transition band를 위한 추가 주파수 영역을 확보하기 위함.
Quantization
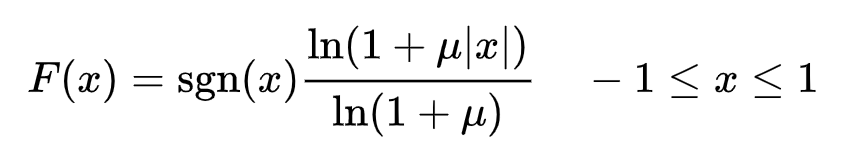
def uLaw_d(i8bit):
bias = 33
sign = pos = 0
decoded = 0
i8bit = ~i8bit
if i8bit&0x80:
i8bit &= ~(1<<7)
sign = -1
pos = ( (i8bit&0xf0) >> 4 ) + 5
decoded = ((1 << pos) | ((i8bit & 0x0F) << (pos - 4)) | (1 << (pos - 5))) - bias
return decoded if sign else ~decoded
def uLaw_e(i16bit):
MAX = 0x1fff
BIAS = 33
mask = 0x1000
sign = lsb = 0
pos = 12
if i16bit < 0:
i16bit = -i16bit
sign = 0x80
i16bit += BIAS
if ( i16bit>MAX ): i16bit = MAX
for x in reversed(range(pos)):
if i16bit&mask != mask and pos>=5:
pos = x
break
lsb = ( i16bit>>(pos-4) )&0xf
return ( ~( sign | ( pos<<4 ) | lsb ) )
normal : 255 | FF : 0000000011111111
encoded: -179 | -B3 : -000000010110011
decoded: 263 | 107 : 0000000100000111
- 양자화는 샘플링된 실수 범위의 이산 신호를 정수 범위의 이산 신호로 변환하는 과정으로, 비트 깊이가 클수록 정보 손실은 줄지만 저장 공간이 늘어남.
- 양자화 잡음을 줄이기 위해 μ-law와 같은 압신(companding) 기법을 사용하여, 신호의 진폭에 따라 양자화 계단의 크기를 비선형적으로 조절.
- 압신이란 압축(compression)과 신장(expanding)을 동시에 일컫는 용어
- 인코딩은 디지털 변환된 오디오 신호를 전송, 저장 가능한 형식(wav, flac, mp3 등)으로 바꾸는 과정으로, 포맷에 따라 압축 방식이 다르다(wav는 무압축, flac은 무손실 압축, mp3는 손실 압축).
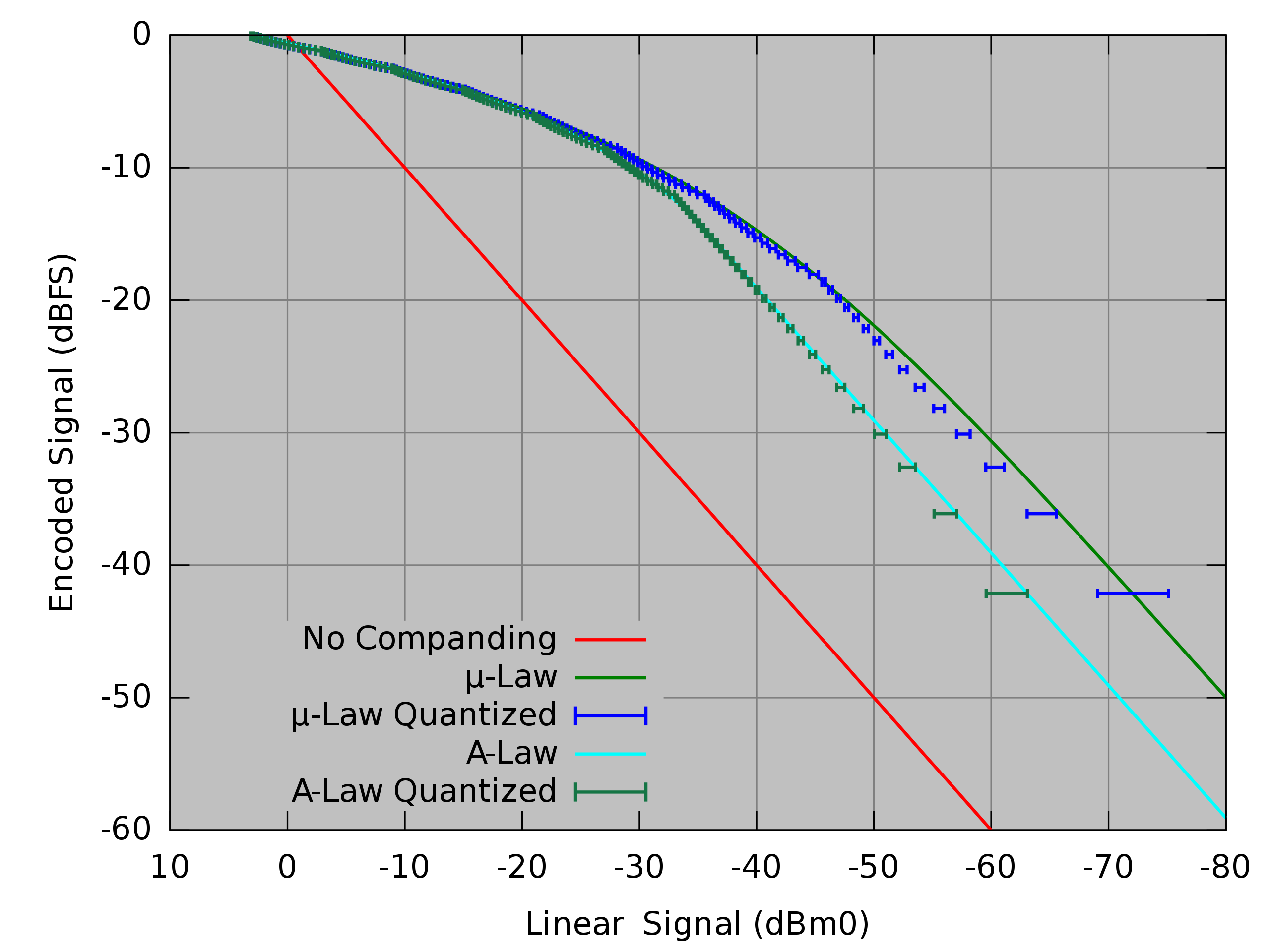
- 사람은 진폭이 작은 신호는 세밀히 인식하고, 진폭이 큰 신호는 상대적으로 덜 세밀하게 인식하는 경향이 있다
- mu-law 는 그런 의미에서 적절한 인코딩을 하고 있다.
Loudness
- Loudness는 음성 신호의 Power와 관계가 있으며, 파워는 신호의 진폭(Amplitude)과 직접적인 관계가 있어, 진폭이 큰 신호일수록 사람은 그 소리를 크고 시끄러운 것으로 인식.
- Power는 이산 신호의 샘플 수에 대한 신호의 제곱값의 평균으로 정의되며, Intensity는 파워를 데시벨(Decibel, dB) 단위로 표현한 것으로, 사람이 들을 수 있는 가장 작은 소리인 P0 대비 얼마나 큰지 나타냄.
- Loudness와 Power의 관계는 Linear가 아니며, 사람은 Power가 작은 음성 신호를 더 세밀하게 인식하고, 또한 특정 주파수(Frequency)의 신호를 상대적으로 크게 인식하는 경향이 있다. (μ-law를 설계할 때 진폭이 작은 입력 신호를 조밀하게 양자화한 것과 연계)
Pitch
- Pitch는 음성 신호의 주파수에 따른 높낮이로, 사람은 100Hz부터 1000Hz까지의 주파수에서 피치를 선형적으로 인식하고, 1000Hz 이상에서는 주파수에 따른 피치 인식이 로그 형태로 변화.
- 멜 스케일(mel scale)은 인간의 피치 인식을 균일하게 반영하기 위해 도입된 척도로, 저주파 영역에서는 세밀한 변화를, 고주파 영역에서는 더 넓은 간격으로 변화하는 스케일.
- 멜 스케일의 수식 m=1127ln(1+f/700)은 주파수를 멜 단위로 변환하여 인간의 귀가 인식하는 피치의 차이를 보다 일관되게 나타냄.
Vowel
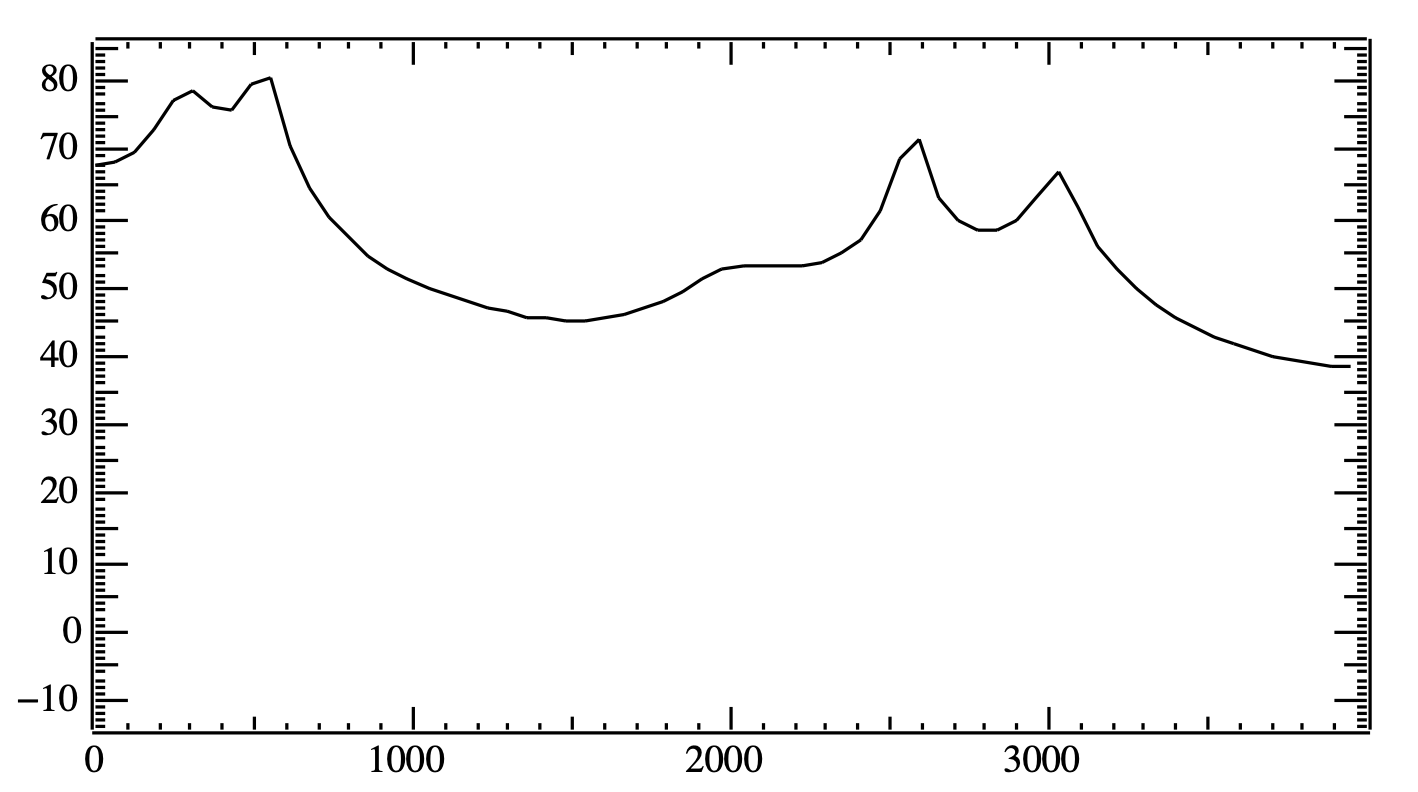
- 모음은 음절의 핵심 요소로, 자음보다 큰 진폭과 규칙적인 패턴을 가지며, 포만트는 모음의 특성을 결정하는 중요한 음향 에너지 봉우리.
- 스펙트럼은 특정 시점의 음성 신호를 주파수 도메인으로 변환한 것이며, 스펙트로그램은 시간에 따른 스펙트럼의 연속으로, 모음의 포만트를 시각적으로 보여줌.
- 음성 인식 기술은 말소리의 포만트 정보 처리를 중요하게 처리.
- 말소리(fundamental frequency)는 기본 주파수와 그 정수배인 배음(harmonics)으로 구성되어 있어, 이는 말소리의 독특한 특징을 결정짓는 요소.
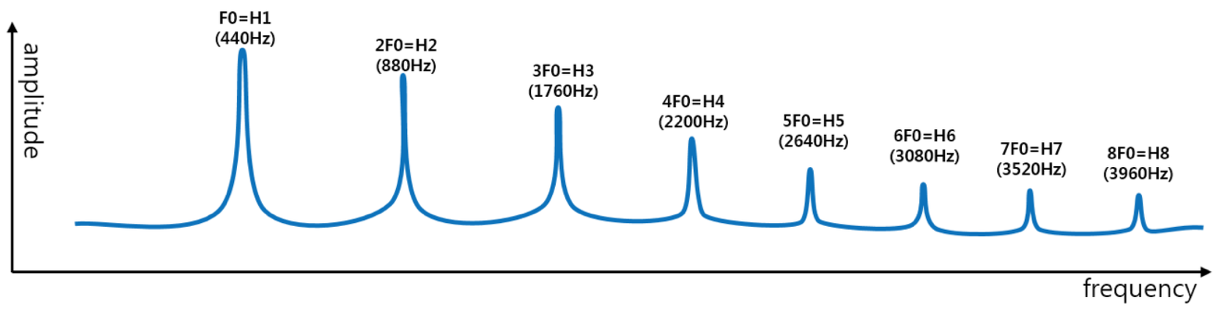
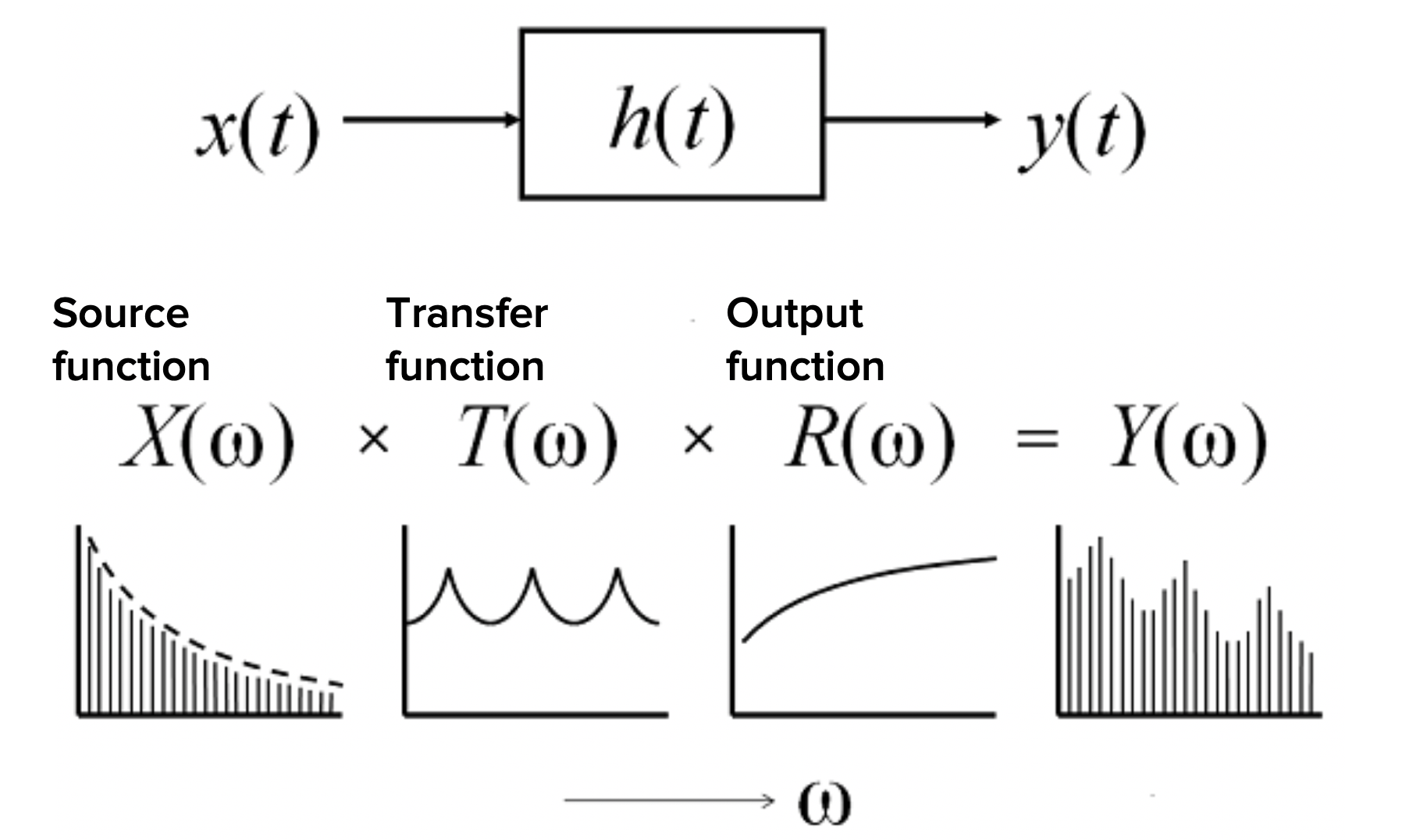
The Source-Filter Model
- Source-Filter Model은 인간의 모음 발음을 설명하는 이론으로, 성문에서 발생하는 소리를 ‘소스’로, 혀와 입술 등 조음 기관의 변화를 ‘필터’로 봐서 발음이 달라짐.
- 개인의 고유한 음색은 ‘소스’의 차이에서 비롯되며, 조음 기관의 공명에 의해 특정 주파수가 강조되거나 약화되어 모음의 특성을 결정하는 포만트가 생성.
- 같은 사람의 소리는 기본적으로 유사하지만, 조음 기관의 형태와 움직임(필터)에 따라 다양한 모음이 생성되며, 다른 사람과의 차이는 각자의 독특한 소스에서 기인.

Comments