
Speech Model Pre-training for End-to-End Spoken Language Understanding
Architecture
Abstract
-
이 논문은 SLU(Spoken Language Understanding) 즉, 음성 이해 시스템에 대한 논문 Ex) Siri, 네이버 클로바
-
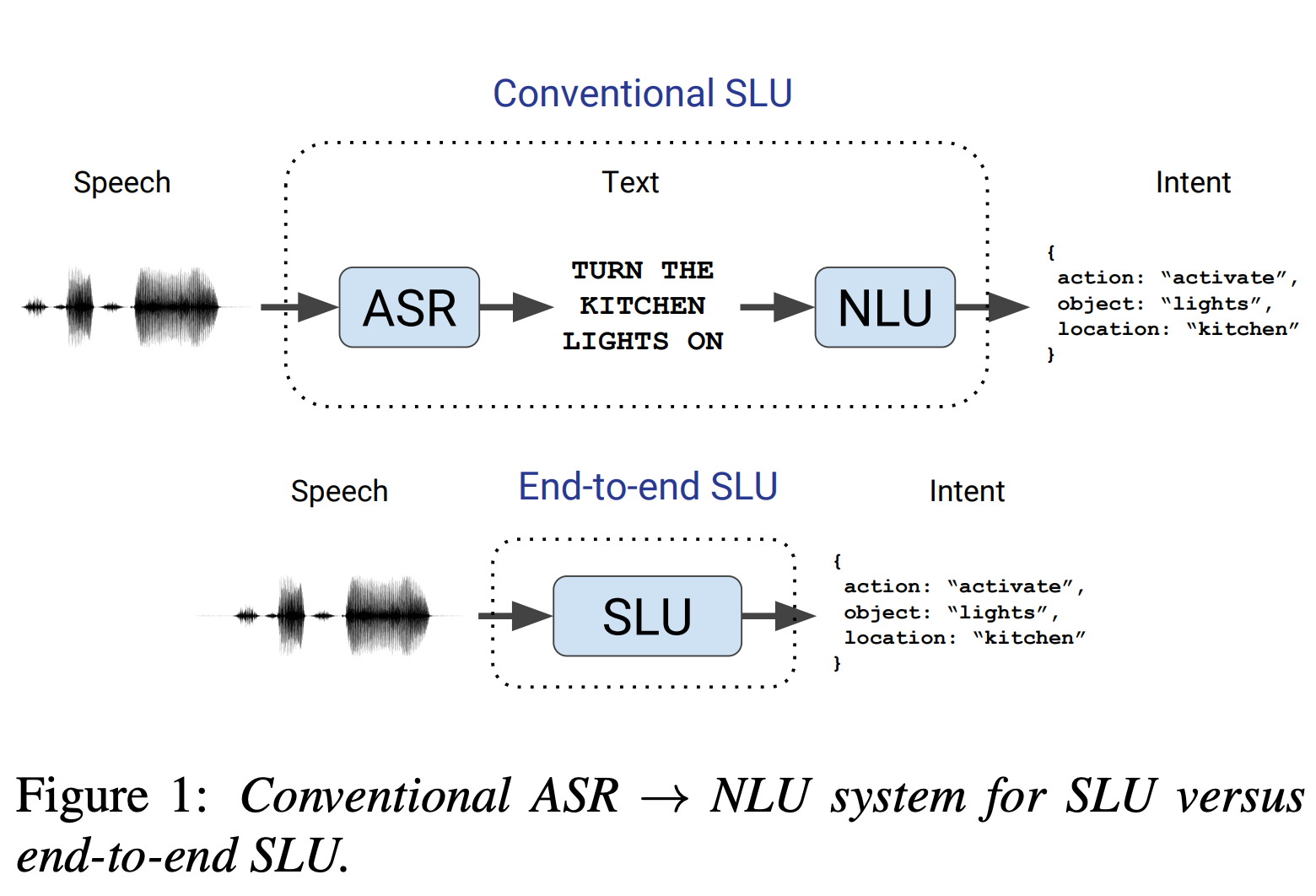
기존 SLU 시스템은 음성 -> Text -> Intent(의도)로 맵핑, 해당 논문은 단일 학습 모델을 통해 직접 Intent 로 변환하는 End to End 시스템 제안.
-
그냥 바로 학습하면 에러율이 높기 때문에, 모델이 단어와 음소를 예측하도록 사전 훈련(Pre-trained), 이후 모델을 전이 학습
-
SLU 을 학습하기 위한 Dataset 이 부족하기 때문에 Fluent Speech Commands Dataset을 구축 (관련 사업을 하는 회사에서 생성한 데이터)
-
이 데이터셋은 소규모, 대규모 학습시 모두 성능이 좋게 나옴, 일반화 능력 또한 상승시키는데 기여, 그리고 무료
Introduction
SLU Example
“우유 두 개와 설탕 한 개를 넣어 큰 사이즈 커피를 만들어 주세요” 를 모델에 음성으로 주입 할 때 아래와 같은 Json 형태로 변환하는 것
{
drink: "coffee",
size: "large",
additions: [
{type: "milk", count: 2},
{type: "sugar", count: 1}
]
}
전통적인 SLU 파이프라인
- 음성을 텍스트 대본으로 매핑하는 자동 음성 인식(ASR) 모듈
- 텍스트 대본을 발화자의 의도로 매핑하는 자연어 이해(NLU) 모듈
해당 논문 발표 당시 연구 트랜드
- End to End (종단간) SLU
- 단일 훈련 가능한 모델이 명시적으로 텍스트 대본을 생성하지 않고 직접 음성 오디오를 발화자의 의도로 매핑
End to End 의 장점
-
관심 있는 메트릭(Intent 인식 정확도)을 직접 최적화 가능
-
텍스트를 위한 모델링을 안함. 간결한 모델을 제공하고 검색 알고리즘, 언어 모델, 유한 상태 변환기 등을 포함하는 오류가 발생하기 쉬운 중간 단계를 피할 수 있다.
-
텍스트 대본에는 나타나지 않는 Intent를 추론하는 데 관련이 있을 수 있는 발화의 억양을 활용할 수 있음
End to End 를 구현할 때 문제
SLU의 파이프라인을 표현하면 다음과 같음
파형 → 음소 → 형태소 → 단어 → 개념 → 의미
단일 화자에 대해서도 변동성이 크기 때문에 학습 데이터가 많이 필요함
하지만 SLU는 컴퓨터 비전, ASR 등 다른 영역에 비해 데이터가 많이 부족한 상황(이었음)
Contribution
-
현상황 SLU의 현실적인 실험 방법 (사전학습)
-
생성한 데이터와 코드를 오픈소스로 제공함 (근데 논문에 적힌 링크로는 데이터 접근이 안됨.. )
fluent.ai/research/fluent-speech-commands/
Dataset
-
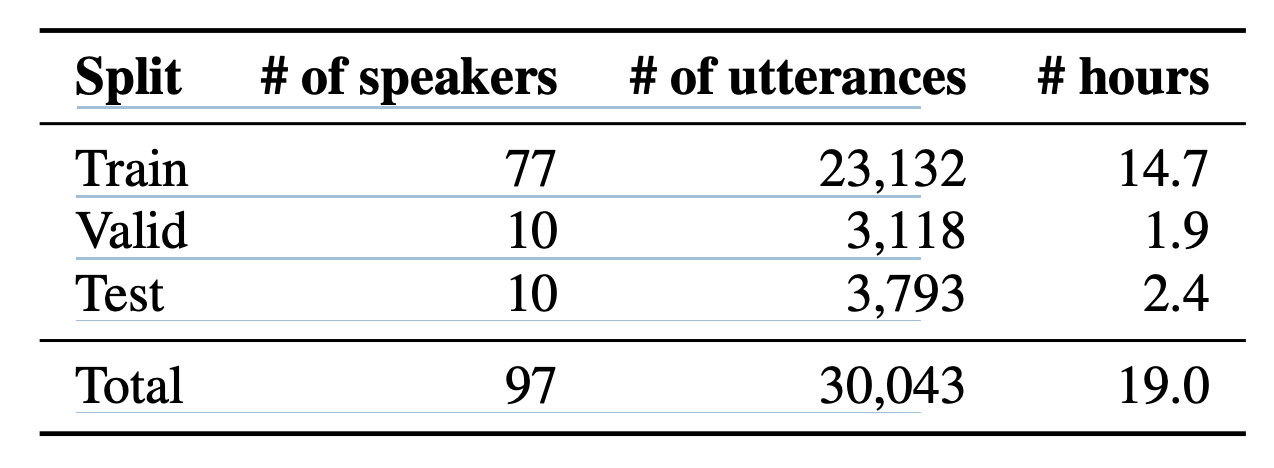
데이터셋은 16 kHz 단일 채널 .wav 오디오 파일로 구성
-
“음악을 틀어줘” 또는 “주방의 난방을 높여줘” 같은 오디오가 녹음되어 있음
-
동작(action), 객체(object), 위치(location) 를 각각 슬롯으로 지정하고 그 안에 여라 데이터가 존재
-
슬롯 값의 조합이 발화의 의도(intent)
{action: "activate",
object: "lights",
location: "none"}
- 원어민과 비원어민 영어 사용자를 포함
Data Collection
-
각 문구를 두 번씩 말하며 녹음
-
녹음할 문구들은 무작위 순서로 제시
-
동의를 통해 개인정보 이슈 해결
-
데이터는 별도의 크라우드소싱 집단에 의해 검증
-
train, valid, test 로 나뉨
-
특정 intent 는 하나의 split에만 존재하게 해서 일반화 테스트를 진행
Related Dataset
-
Google Speech Commands dataset
-
ATIS
-
Grabo
-
Domotica
-
Patcor
Model and Pre-training Strategy
-
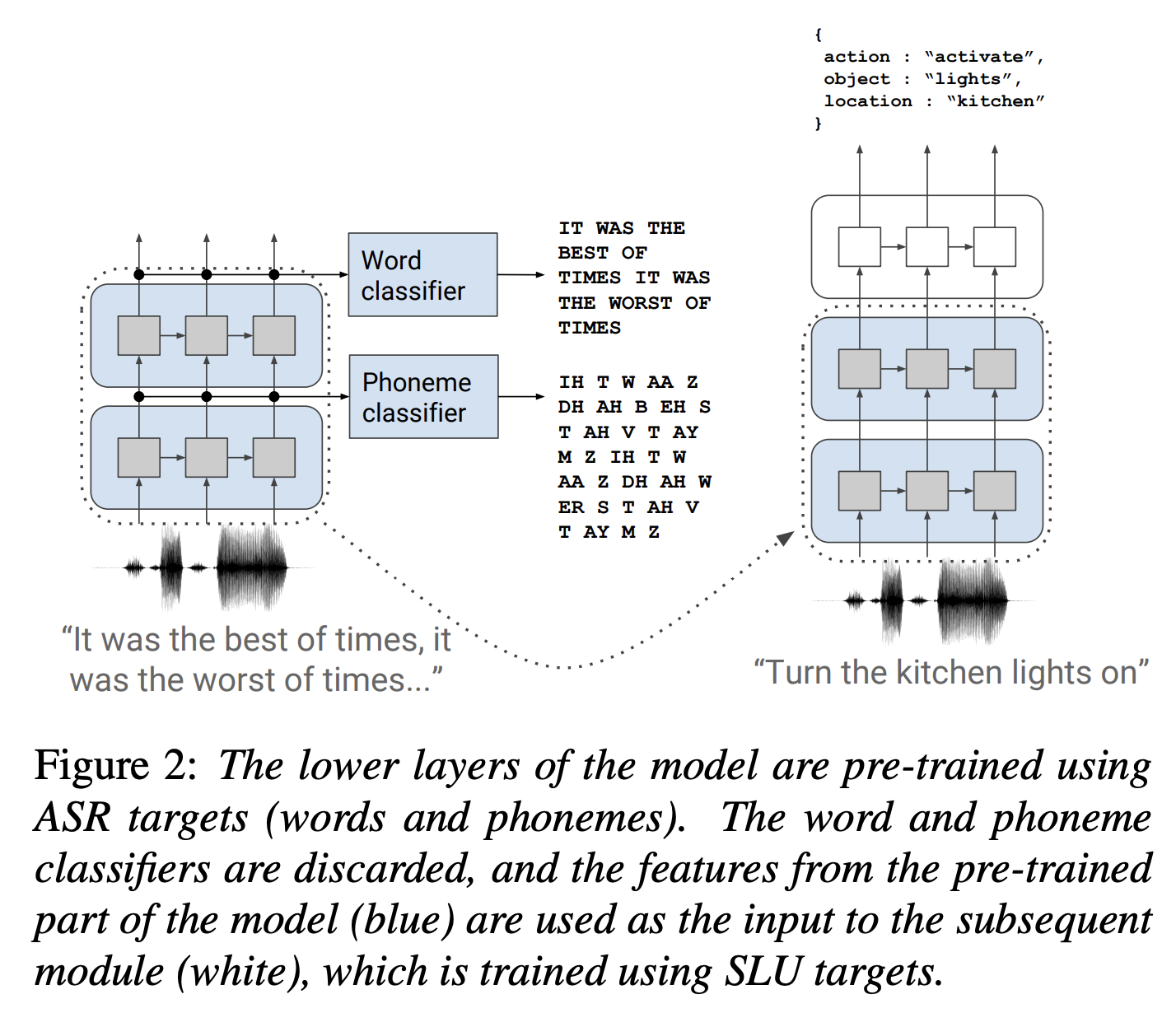
음소와 단어를 예측하도록 사전 훈련된 첫 번째 모듈이 있는 모듈 스택으로 심층 신경망
-
이후 단어 및 음소 분류기는 제거, 전체 모델은 SLU 작업에 대해 처음부터 끝까지 훈련
-
960시간의 LibriSpeech 데이터 셋을 이용하여 학습
-
전체 발화 대신 짧고 무작위로 자른 조각을 사용하여 사전 훈련함 (이게 효과가 좋았다고 한다)
[Note] Montreal Forced Aligner (MFA)
음성과 텍스트의 Algin 을 지원하는 도구
- 자동 음소 정렬- 음성 녹음과 대응하는 텍스트를 기반으로 자동으로 음소 경계 찾기
- 여러 언어에 대한 음소 집합과 발음 사전 지원
Phoneme Module
아래와 같이 음소 모델을 구축
l_phoneme = W_phoneme * h_phoneme + b_phoneme.
(1) Hidden Representation 시퀀스인 h_phoneme을 사용 (2) 음소 모듈은 원시 입력 파형을 처리하는 SincNet 레이어를 사용 (3) 여러 개의 컨볼루션 레이어와 순환 레이어가 풀링(시퀀스 길이를 줄이기 위해)과 드롭아웃과 함께 사용
Word module
l_word = W_word * h_word + b_word.
(1) 두 번째 모듈은 h_phoneme을 입력으로 받아 h_word를 출력
(2) 음소 모듈과 유사하게 드롭아웃과 풀링이 있는 순환 레이어를 사용,
(3) 다른 선형 분류기를 사용하여 전체 단어 대상을 예측하도록 사전 훈련
(4) 이 모듈의 입력은 l_phoneme이 아닌 h_phoneme이고, 마찬가지로 다음 단계로의 출력이 l_word가 아닌 h_word
h 대신 l을 전달하는 두 가지 이유
(1) 모델의 자유도 유지 - l의 크기는 대상의 수에 의해 고정되며, 이는 차례로 모델의 다음 레이어의 크기가 고정됨
(2) l_word를 계산하는 것은 큰 (약 250만 개의 매개변수에 해당하는) 가중치 행렬을 곱하고 저장하는 것이 필요
Intent Module
(1) 사전 훈련되지 않은 세 번째 모듈은 h_word를 Intent로 맵핑하는 모듈
(2) recurrent layer를 사용하여 구현
(3) recurrent layer 의 결과를 단일 로짓 벡터로 압축하기 위해 맥스 풀링을 진행
followed by max-pooling to squash the sequence of outputs from the recurrent layer into a single vector of logits corresponding to the different slot values
Experiments
-
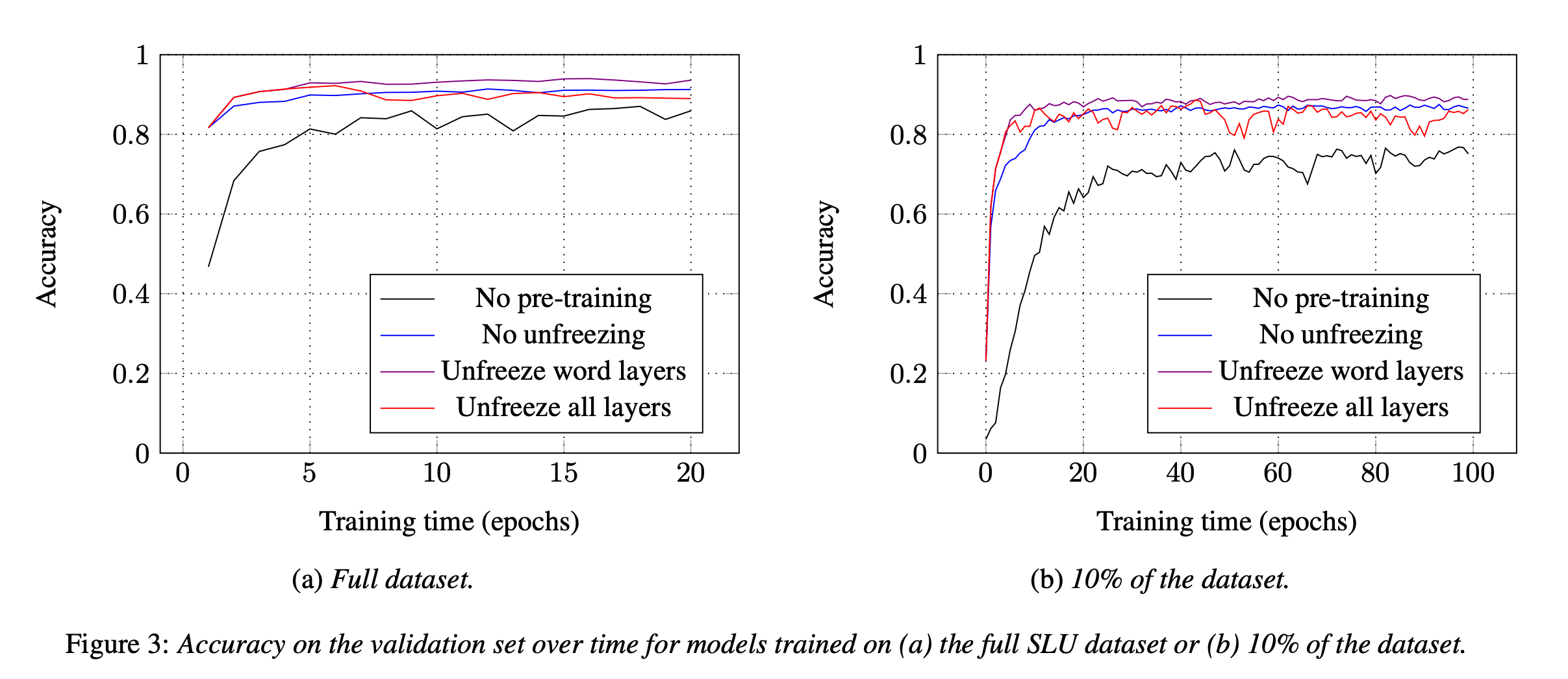
사전 학습을 하고 vs 안하고 테스트
-
사전 학습 레이어를 해제하고 vs 안하고 테스트
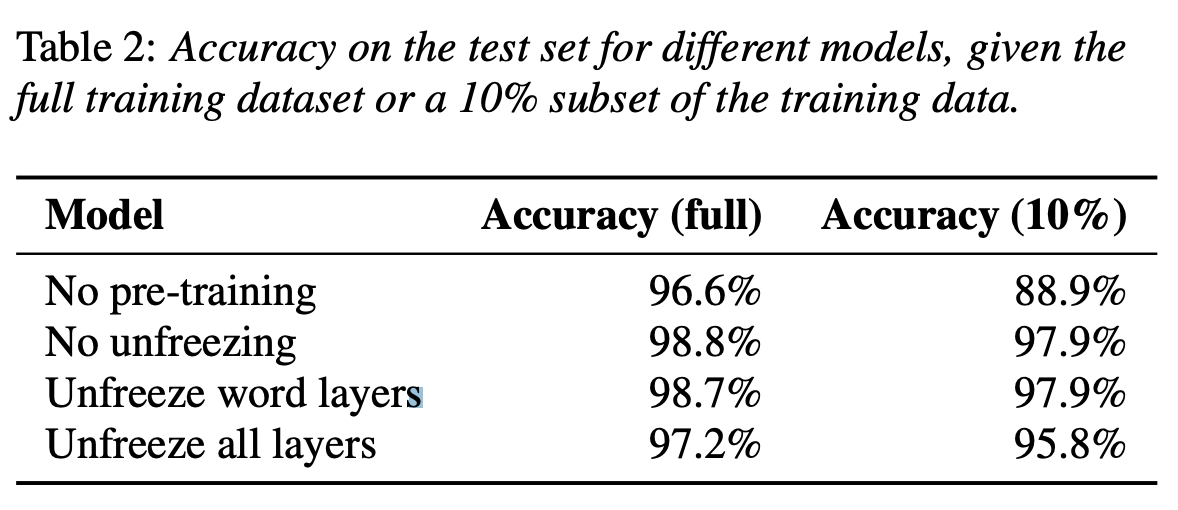
- 데이터 사이즈를 작게 vs 크게하여 테스트
Generalizing to new wordings
-
새로운 문구 일반화 문제: 모든 가능한 문구를 훈련 데이터에 포함시키는 것은 비현실적
-
사전 훈련의 효과: 사전 훈련된 모델은 새로운 문구에 대해 높은 정확도로 일반화 가능, “turn on/off the lights” , “switch on the lights”에 대해 훈련된 모델이 “switch off the lights”라는 문구를 인식
-
일반화 한계와 임베딩 활용: 모델이 “bedroom”과 “washroom”만을 훈련 데이터로 사용했을 때 “bathroom”과 같은 새로운 용어를 잘못 추론하는 등의 일반화 한계 보임.
-
NLU에서는 단어 임베딩을 사용하여 유사한 의미의 단어가 유사한 벡터로 구성하여 이 문제를 해결할 수 있다. 이와 유사한 방법으로 사전 훈련된 모델을 학습하면 일반화 문제를 개선할 수 있을 것으로 기대
Conclusion
-
dataset 구축
-
End to End를 사전학습을 통해 구축
Code
Pre-Train : https://github.com/lorenlugosch/end-to-end-SLU/blob/master/models.py#L170
decode 이후 결과 출력 : https://github.com/lorenlugosch/end-to-end-SLU/blob/e94bd479de1a82663c38363979309089acebcd36/models.py#L868
phone loss : https://github.com/lorenlugosch/end-to-end-SLU/blob/e94bd479de1a82663c38363979309089acebcd36/models.py#L312
intent loss : https://github.com/lorenlugosch/end-to-end-SLU/blob/e94bd479de1a82663c38363979309089acebcd36/models.py#L817
Improvement
Attention Version : https://github.com/lorenlugosch/end-to-end-SLU/blob/e94bd479de1a82663c38363979309089acebcd36/models.py#L721

Comments