
FastSpeech: Fast, Robust and Controllable Text to Speech
Abstract
기존 모델의 구조
- 기존의 Text-to-Speech (TTS) 모델들은 텍스트에서 mel-spectrogram을 생성한 후, WaveNet과 같은 vocoder를 사용하여 이 mel-spectrogram에서 음성을 합성
기존 모델의 단점
- 기존 end-to-end TTS 모델들은 추론 속도가 느리며, 합성된 음성이 일관성이 없다. (예: 단어를 빠뜨리거나 반복)
- voice speed or prosody control 부족
해결책
- phoneme duration 예측을 위해 encoder-decoder 기반의 teacher 모델에서 추출한 attention alignment 사용
- phoneme 시퀀스를 대상 mel-spectrogram 시퀀스의 길이에 맞게 확장하는 length regulator를 통해 mel-spectrogram을 병렬로 생성
결과
- 생성 속도 270배, 전체 음성 합성 속도를 38배 향상
Introduction
Tacotron, Deep Voice 등과 같은 기존 TTS 모델은 autoregressive 하게 mel-spectrogram을 생성한 다음, vocoder를 사용하여 mel-spectrogram에서 음성을 합성함
[NOTE] 자기 회귀 모델. 시퀀스의 이전 입력에서 측정값을 가져와 시퀀스의 다음 성분을 자동으로 예측하는 기계 학습
긴 mel-spectrogram 시퀀스와 autoregressive 특성으로 인해 기존 TTS 모델은 한계점이 존재
- Mel-spectrogram 생성으로 인한 느린 추론 속도
- CNN, Transformer 기반 모델은 RNN 기반 모델보다 추론 속도를 빠르게 할 수 있음
- 일반적으로 mel-spectrogram 시퀀스의 길이는 수백~수천이므로 여전히 추론 속도가 느림
- 합성된 음성은 robust하지 않음
- Autoregressive 생성 단계에서의 error propagation, 잘못된 attention alignment로 인해 생성된 mel-spectrogram은 word skipping, repeating 문제를 보임
- 합성된 음성은 controllability가 부족함
- Autoregressive 모델은 text와 음성 사이의 alignment를 명시적으로 활용하지 않고 mel-spectrogram을 하나씩 생성함
- 즉, Voice speed, prosody를 control 하기 어려움
그래서 FastSpeech 를 만듬
Fast Speech
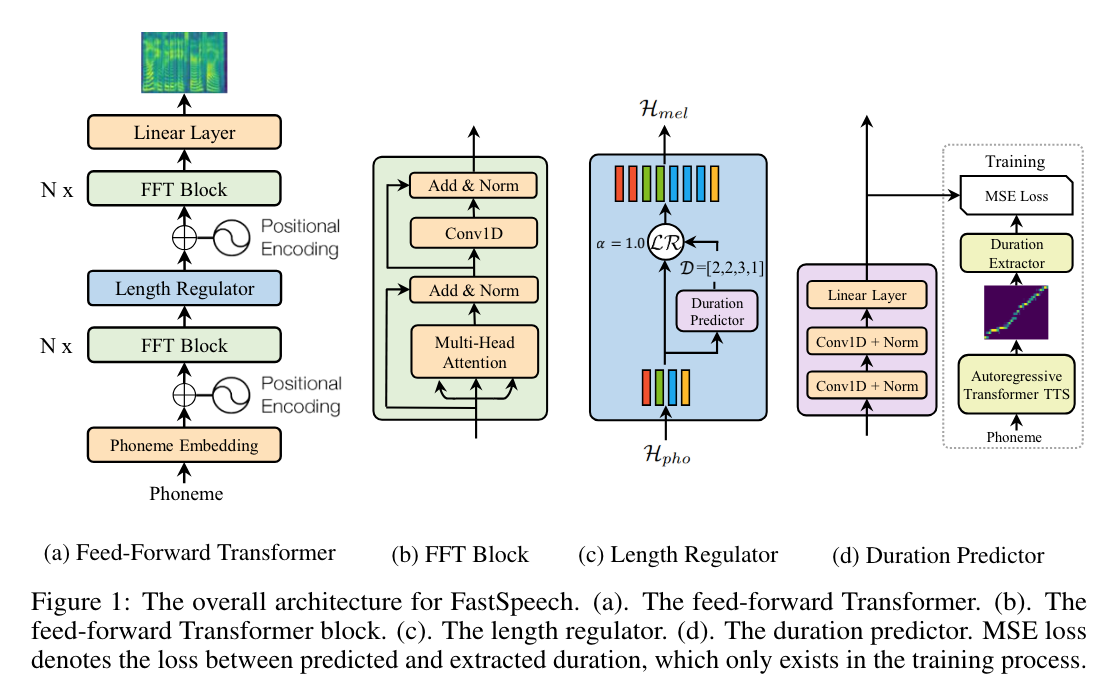
-
텍스트(음소) 시퀀스를 입력으로 받아 mel-spectrogram을 non-autoregressively 으로 생성, 이전 것을 몰라도 되므로 병렬 처리 가능
-
Parallel Mel-Spectrogram Generation: FastSpeech는 parallel processing을 통해 mel-spectrogram의 생성 과정을 크게 가속화.
-
Length Regulator: Phoneme duration을 조정하여 speech speed를 쉽게 조절. adjacent phoneme 사이에 breaks를 추가함으로써 speech의 prosody 일부를 제어.
-
Phoneme Duration Predictor: Phoneme과 해당 mel-spectrogram 간의 alignment를 보장. autoregressive 모델의 soft 및 automatic attention alignment와 달리 error propagation과 잘못된 attention alignment 문제를 방지하며, skipped words와 repeated words의 비율을 줄임.
-
Feed-Forward Transformer
Transformer의 self-attention, 1D convolution에 기반한 feed-forward 구조
- Phoneme에서 mel-spectrogram 변환을 위해 여러개의 FFT 블록을 stack 함 Phoneme 쪽에 N개의 블록, mel-spectrogram 쪽에 N개의 블록이 사용
- Phoneme과 mel-spectrogram 시퀀스 사이의 length gap을 length regulator로 연결 Self-attention network는 cross-position 정보를 추출하기 위한 multi-head attention으로 구성
- ReLU activation을 포함한 2-layer 1D convolution network의 사용
- 기존 transformer에서 2-layer Dense network를 대체
- Adjacent hidden state가 character / phoneme 및 mel-spectrogram 시퀀스에 더 밀접하게 관련되어 있다는 점을 이용
- Transformer에서 residual connection, layer normalization, dropuout이 self-attention 및 1D convolution network 다음에 추가됨
Length Regulator
- Feed-Forward Transformer에서 phoneme sequence와 spectrogram sequence 간의 길이 불일치 문제를 해결
- voice speed 및 prosody의 일부를 제어하는데 사용
- Phoneme sequence의 길이는 일반적으로 해당 mel-spectrogram sequence의 길이보다 작다.
- phoneme은 여러 mel-spectrogram에 해당 Phoneme duration은 phoneme에 해당하는 mel-spectrogram의 길이로 표현.
[NOTE] phoneme sequence ([h1, h2, h3, h4])와 해당 phoneme duration ([2, 2, 3, 1])에 대해, 정상 속도(alpha = 1)에서 확장된 sequence는 ([h1, h1, h2, h2, h3, h3, h3, h4])가 됨
[NOTE] 느린 속도(alpha = 1.3)에서는 ([h1, h1, h1, h2, h2, h2, h3, h3, h3, h3, h4])
[NOTE] 빠른 속도(alpha = 0.5)에서는 ([h1, h2, h3, h3, h4])
Duration Predictor
Phoneme duration predictor는 2 layer의 1D convolutional network와 추가적인 linear layer를 통해 phoneme의 지속 시간을 예측
FastSpeech 모델과 함께 훈련되어 각 phoneme에 대한 mel-spectrogram의 길이를 MSE loss로 예측
Phoneme duration predictor 는 TTS의 추론 단계에서만 사용
훈련시에는 autoregressive teacher 모델로부터 추출한 phoneme 지속 시간을 직접 사용
-
Autoregressive Transformer TTS 모델 훈련: autoregressive encoder-attention-decoder 기반 Transformer TTS 모델을 훈련
-
Attention Alignments 추출: 훈련된 teacher 모델로부터 각 훈련 시퀀스 쌍에 대해 decoder-to-encoder attention alignments를 추출. multi head self-attention으로 인해 여러 attention alignments가 존재하며, 가장 대각선에 가까운 attention head를 선택하기 위해 focus rate (F)를 계산하고, 가장 큰 (F) 값을 가진 head를 선택.
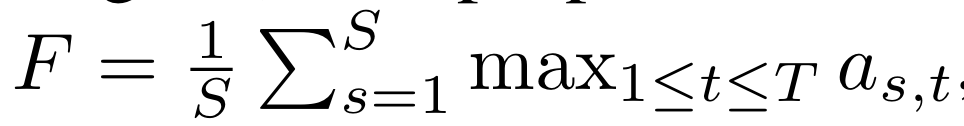
- S,T : 각각 ground-truth spectrogram과 phoneme 길이
- as,t : attention matrix의 s 번째 row와 t 번째 column의 element
- Phoneme Duration Sequence 추출: 선택된 attention head에 따라 각 phoneme이 주목하는 mel-spectrogram의 수를 나타내는 phoneme duration sequence (D = [d1, d2, …, dn])를 추출. 이 과정을 통해 각 phoneme의 지속 시간을 결정.
Experimental Setup
- Settings
- Dataset : LJSpeech
- Comparisions : Tacotron 2, Transformer TTS, Merlin
- Results
- Audio Quality- Transformer TTS, Tacotron 2와 비슷한 음성 합성 품질을 달성

Audio Quality
[NOTE] MOS (Mean Opinion Score)는 음성이나 비디오와 같은 멀티미디어의 품질을 평가하는 데 사용되는 척도. 주로 음성 통신과 오디오/비디오 스트리밍 서비스의 품질 평가에 사용 인간 평가자들이 제공한 평가의 평균값으로 계산 MOS가 높을수록 평가 대상의 품질이 좋다고 인식
Inference Speedup
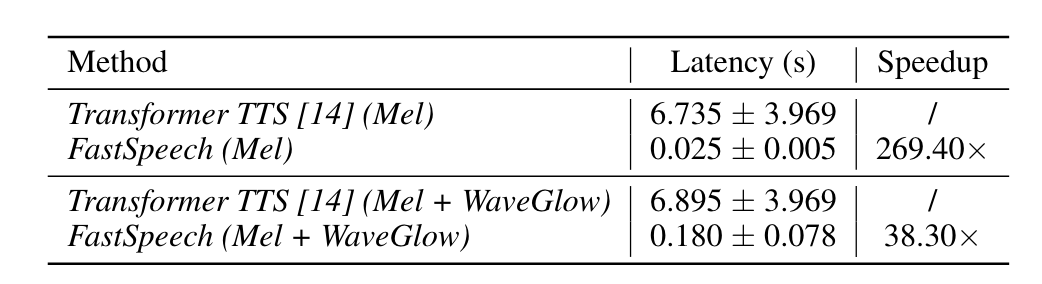
spec : 12 Intel Xeon CPU, 256GB memory, 1 NVIDIA V100 GPU
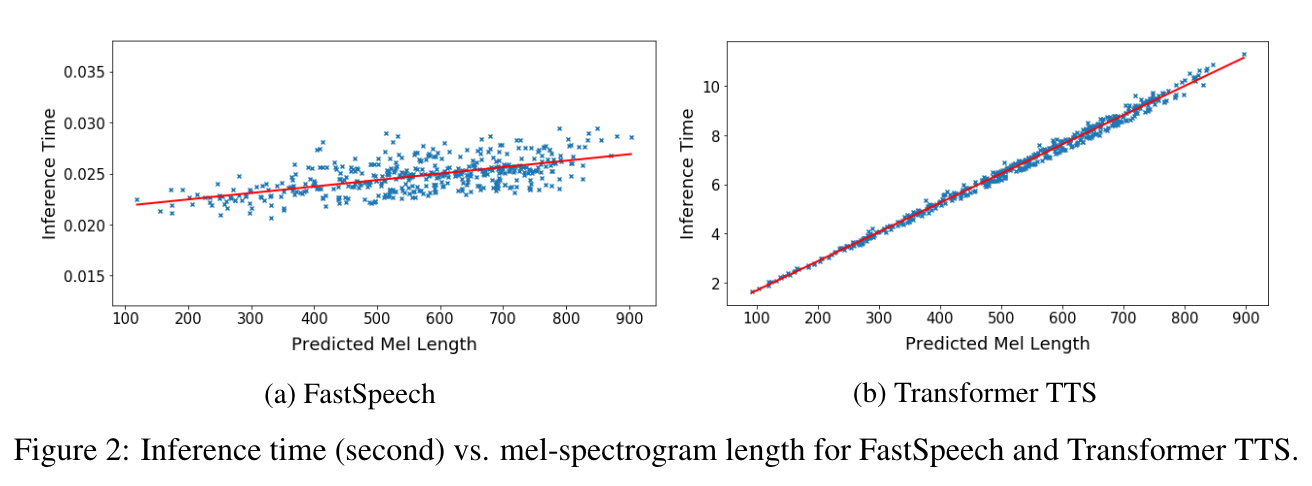
mel length 가 길어져도 inference 시간은 짧다.
Robust
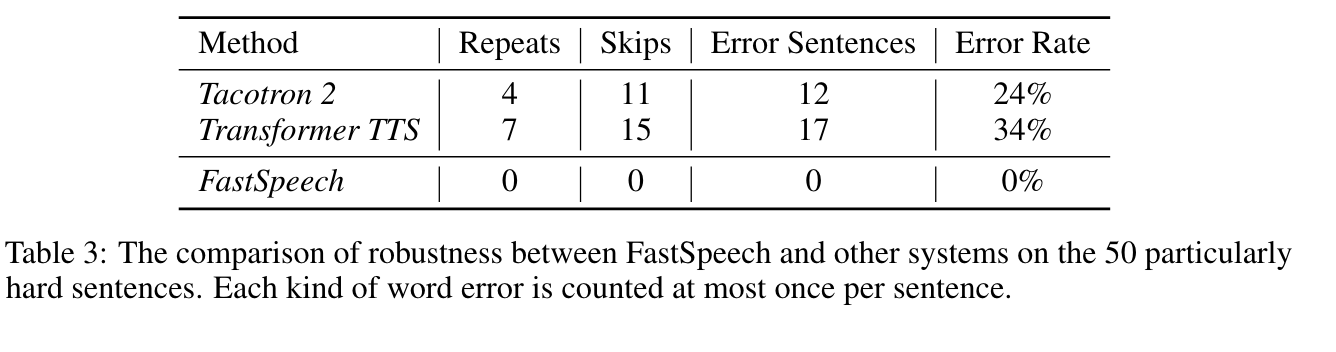
Length Control
Length Control
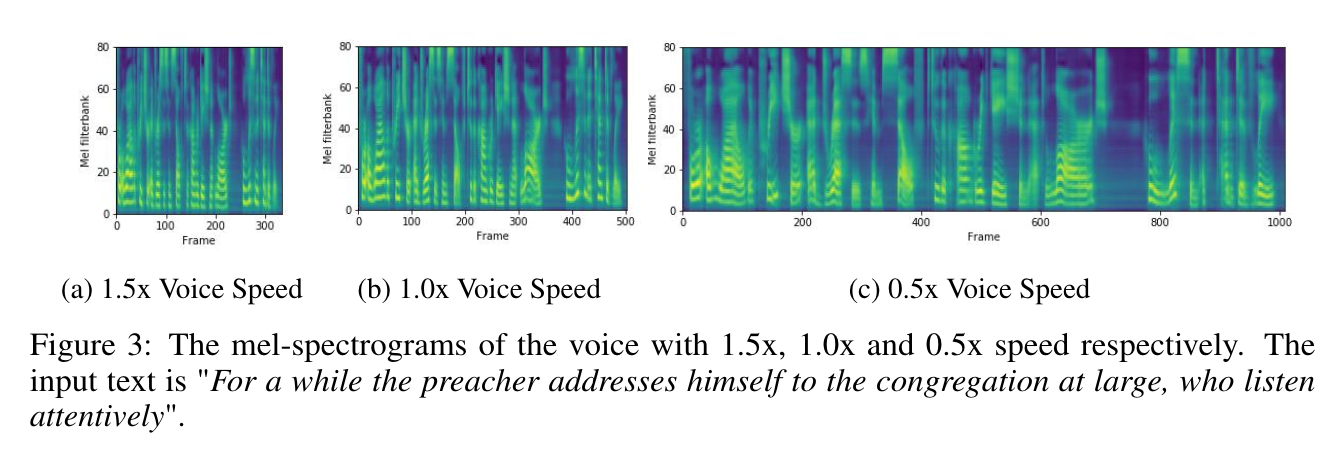
- FastSpeech는 phoneme duration을 조정하여 prosody와 voice speed를 조정할 수 있음
- Length 조절 전후의 mel-spectrogram을 비교
- Voice Speed
- FastSpeech는 voice speed를 0.5~1.5까지 안정적인 pitch로 변환할 수 있음
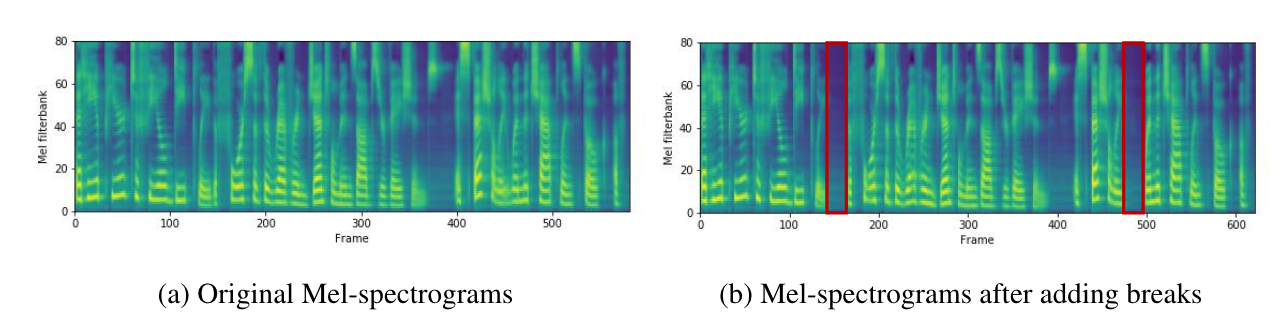
- Breaks Between Words
- FastSpeech는 문장에서 space character의 duration을 늘려 adjacent word 간의 break를 조절해 voice prosody를 개선할 수 있음
Ablation Study
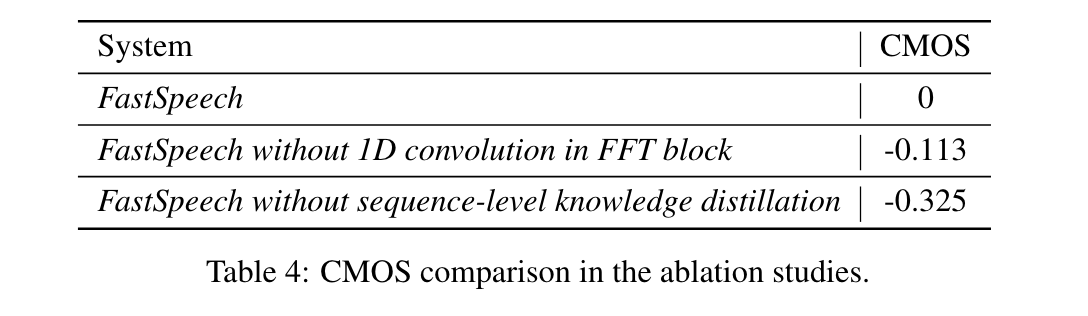
FastSpeech에서 1D convolution과 Sequence-level Knowledge Distillation 효과 비교
- 1D convolution in FFT
- FFT는 기존의 fully-connected layer 대신 1D convolution을 사용함
- 1D convolution 대신 fully-connected layer를 사용한 경우, -0.113 CMOS를 달성해 성능 저하를 보임
- Sequence-level Knowledge Distillation
- Knowledge distillation을 사용하지 않은 경우, -0.325 CMOS를 달성해 성능 저하를 보임
Conclusions
- 이 연구는 빠르고, 견고하고, 제어 가능한 신경망 TTS 시스템인 FastSpeech를 제안;
- 병렬로 mel-spectrogram을 생성하는 새로운 피드-포워드 네트워크를 포함
- 음성 품질 면에서 autoregressive Transformer TTS 모델에 거의 맞먹고, mel-spectrogram 생성을 270배, end-to-end 음성 합성을 38배 가속화하며, 단어 건너뛰기와 반복 문제를 거의 해결하고, 음성 속도를 원활하게 조절할 수 있다.

Comments