
FastSpeech 2: FAST AND HIGH-QUALITY END-TOEND TEXT TO SPEECH
Abstract
-
FastSpeech와 같은 non-autoregressive Text-to-Speech (TTS) 모델은 빠르게 음성합성이 가능
-
FastSpeech는 duration prediction과 knowledge distillation을 위해 autoregressive teacher 모델에 의존적
-
Teacher-student distillation 과정이 복잡하고 시간 소모적
-
Teacher 모델에서 추출한 duration이 정확하지 않고 target mel-spectrogram의 단순함으로 인해 정보 손실이 발생함
FastSpeech 2
Teacher의 단순화된 output 대신 ground-truth를 직접 학습하여 one-to-many 매핑 문제 해결
TTS 의 one-to-many issue의 예시 : multiple speech, variations correspond to the same text
Conditional input에 대한 음성의 variation information (pitch, energy, duration) 도입
Introduction
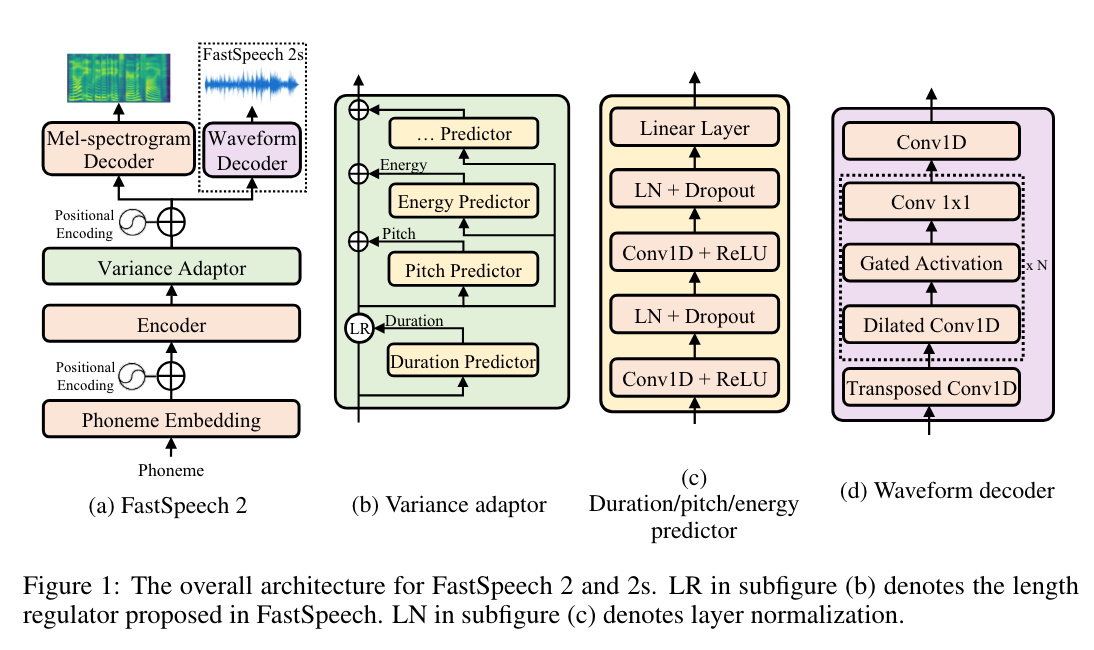
FastSpeech는 one-to-many 매핑을 쉽게하지만 단점도 존재
-
Two-stage teacher-student training은 모델 학습 과정을 복잡하게 만듦
-
Teacher 모델에서 생성된 target mel-spectrogram은 ground-truth에 비해 정보 손실이 존재함
-
생성된 mel-spectrogram으로부터 합성된 오디오 품질은 ground-truth보다 좋지 않기 때문
-
Teacher 모델의 attention map에서 추출한 duration이 정확하지 않음
FastSpeech 2
-
Teacher-student distillation에서 data 단순화로 인한 정보 손실을 방지하기 위해 teacher의 output 대신 ground-truth target으로 FastSpeech2를 직접 학습시킴
-
Text 시퀀스와 mel-spectrogram 사이의 information gap을 줄이고 non-autoregressive TTS의 one-to-many 매핑 문제를 해결하기 위해 pitch, energy, duation을 포함한 variation information을 도입
-
학습 단계에서는 target speech waveform에서 직접 추출하고 추론 단계에서는 예측된 값을 사용
-
Pitch가 가장 중요하고 예측하기 어려운 점을 고려해 continuous wavelet transform을 활용
-
음성 합성을 단순화하기 위해 mel-spectrogram을 intermediate output으로 사용하지 않고 text로부터 직접 음성을 생성하는 FastSpeech 2s 제시
Duration Predictor
음성이 얼마나 오래 들리는지를 나타냄
Pitch Predictor
감정을 전달하는 핵심 특징으로 speech prosody에 큰 영향을 미침
Energy Predictor
mel-spectrogram의 frame-levle magnitude를 나타냄, 음성의 prosody, volume에 영향을 미침
FastSpeech 2s
End-to-end waveform 생성
adversarial training을 도입하여 자체적으로 phase information을 implicitly recover 하도록 함.
FastSpeech 2 mel-spectrogram decoder의 활용

Comments