
Listen, Attend and Spell
Introduction
LAS(Listen, Attend and Spell)는 제안 당시 주류를 이루고 있었던 HMM(Hidden Markov Model) 기반 기존 음성 인식 시스템과 달리 모든 컴포넌트를 End-to-End로 학습할 수 있어 주목을 받았다.
기존 ASR 모델들은 아래와 같이 세가지 모델로 구분 되어있다.
- 발음 모델(pronunciation model) : 단어(word)를 음소 시퀀스(phoneme sequence)에 매핑해주는 역할. 기존 음성 인식 시스템에서는 사전(lexicon)이 이 역할을 수행.
- 음향 모델(acoustic model) : 음소와 음성 사이의 관계를 추론하는 모델. 기존 시스템에서는 Hidden Markov Model + Gaussian Mixture Model이 이 역할을 수행.
- 언어 모델(language model) : 단어 시퀀스의 출현 확률을 부여하는 모델. 기존 시스템에서는 통계 기반의 n-gram 모델이 이 역할을 수행.
하지만 이 모델들은 각각 따로 학습 되었고 그로인해 traning 과정에서 alignment 가 disjoint 되는 이슈가 있었다.
이를 해결하기 위해 speech 를 한번에 transcripts 로 변환하고 이를 traning 하는 end-to-end 방식이 디자인 되었다.
이 논문의 기본적인 접근은 Connectionist Temporal Classification (CTC) 와 sequence to sequence models with attention 의 단점을 해소하고 결합하는데 있다.
-
CTC: 입력 시퀀스의 길이와 출력 시퀀스의 길이가 다를 때 유용하게 사용. 문제는 출력되는 레이블이 각각 독립적이라고 가정하기 때문에 성능의 이슈가 있음. 논문에서는 이런 조건부 독립을 사용하지 않음 -
seq2seq with attention: 어텐션 기법을 사용하여 음소 시퀀스를 다른 음소 시퀀스로 변경하는 방법. 음성에서 음소로 end to end 로 적용하지는 않았음 (도메인의 문제). 논문에서는 음성시그널을 한번에 음소로 바꾸는 것을 적용
그렇기 때문에 이 논문의 가장 큰 기여는 음성신호를 한번에 한 단어씩 변환하면서 시퀀스로 만드는 것 이라고 할 수 있음.
Model
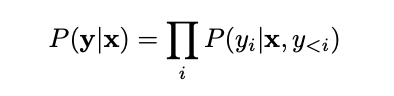
위에서 언급한 것 처럼 LAS 는 기본적으로 독립적이지 않은 모델이다. 이전 시퀀스에 영향을 받아 Y (음소) 를 생성한다.
이를 위해 Listen 단계에서 음성을 음소로 변환한 hidden state h를 생성한다.
이후 AttendAndSpell 단계에서 이전 음소 y 값과 현재 음성 h 값을 받아 확률적으로 새로운 y를 출력한다.
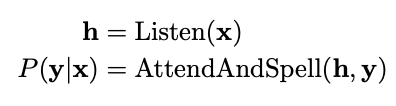
Architecture
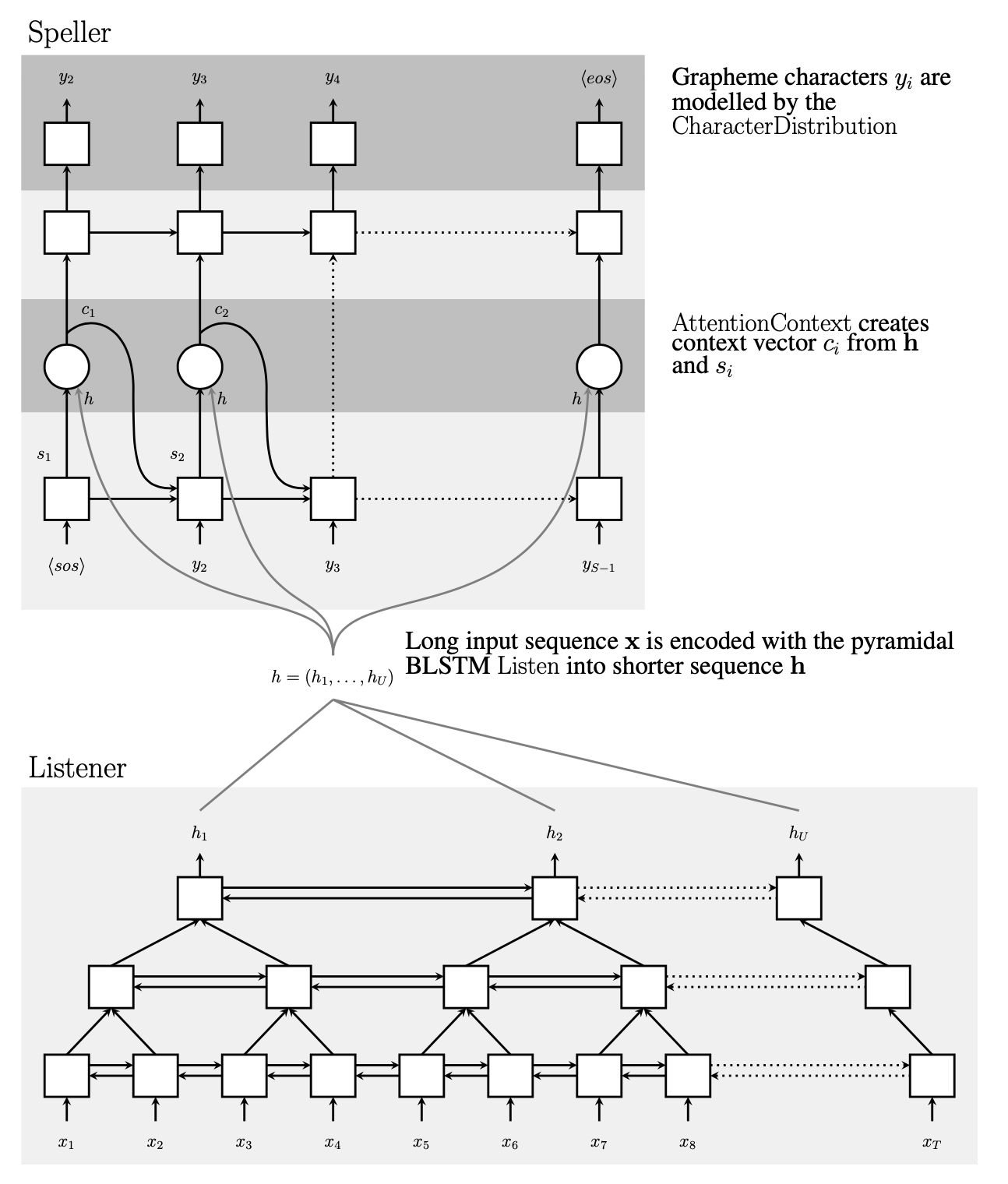
Listener
오디오 시그널을 변환하는 Encoder 역할을 한다. Bidrection LSTM 을 사용하는데, 이는 과거정보와 미래 정보를 한번에 보기 위함이다.
특이한 지점은 BiLSTM 의 output 의 사이즈를 줄이기 위해서 피라미드 형태의 BiLSTM 을 사용한다.
음성의 input 이 워낙 많기 때문에 학습하는데 시간이 너무 오래걸리고 에러율도 높아진다.
또한 어텐션 파라미터를 줄이기 위해서 다음과 같이 사용했다고 한다.
Without the pyramid structure in the encoder side, our model converges too slowly - even
after a month of training.
논문에서는 이를 pBLSTM 이라고 한다.
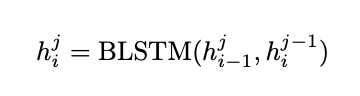
식의 term 중 i는 시간 j는 층을 나타낸다.
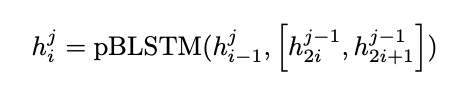
우측 h term 은 이전 Layer에서 온 값.
Speller

Speller는 2개의 순방향 LSTM 레이어로 구성됨. si는 Speller 모듈의 i번째 히든 스테이트
si 에는 직전 시점의 음성 어텐션 정보(Ci-1)와 처음부터 직전 글자까지의 문자 시퀀스 정보(Yi-1)가 포함
이후 AttentionContext 를 통해 새로 받은 listener의 h 를 Attention 하여 Attection Context Ci를 생성한다.
이 값으로 ChracterDistribution(Si,Ci) 를 통해 현재 음소 Yi를 구하게 된다.
이때 논문에서는 음소 한개 한개를 확률을 통해 구하는데, 단어 기준으로 뽑아내는 것이 아닌 음소 단위로 뽑아내기 때문에 out-of-vocabulary (OOV) 이 없다고 한다.
어텐션이 적용되는 공식은 아래와 같다.
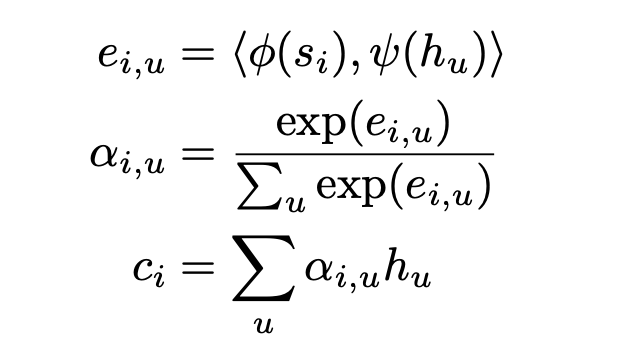
ei,u는 i번째 문자와 u번째 음성 프레임 사이의 스코어(score). 이 값이 높을 수록 해당 문자와 음성 사이의 관계가 깊다. ei,u는 Speller 모듈의 직전 히든 스테이트(si−1)와 Listener 모듈의 히든 스테이트들(h)을 각각 선형변환한 뒤 내적(inner product)하는 방식으로 계산(ϕ,ψ 는 모두 Multi-Layer Perceptron).
어텐션을 이용하기 때문에 LAS는 “triple a” 와 “aaa” 와 같은 유사한 표현을 이해할 수 있다. 또한 실험 중 어텐션 메커니즘이 없으면 모델이 전체적으로 엄청 과적합 되었다고 한다.
Without the
attention mechanism, the model overfits the training data significantly, in spite of our large training
set of three million utterances - it memorizes the training transcripts without paying attention to the
acoustics
Learning
LAS 의 파라미터를 학습하는 과정은 아래와 같다.
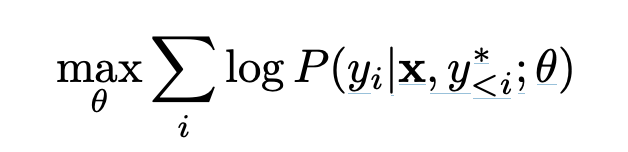
x audio signal 에 대해서 y* (ground truth) 가 있을때, 가장 확률이 높은 y를 내놓는 θ 를 구하는 것.
이때 ground truth y* 를 넣는 것은 오버피팅의 영향이 있기 때문에, 논문에서는 약간의 노이즈를 준다.
일부 예측 된 y hat 을 시퀀스에 넣는 방식이다.
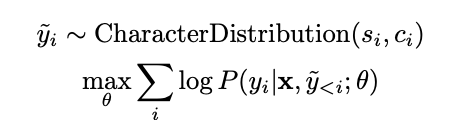
논문에서는 해당 구조가 깊은 deep learning structure 를 갖기 때문에 기존 GMM-HMM 을 통해 사전학습이 필요한지에 대해 확인하기 위해 실험을 했지만 improvement가 없었다고 한다.
Decoding and Rescoring
LAS 의 Inference 를 하는 식은 아래와 같다.
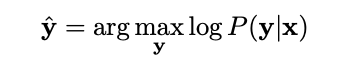
Decoding
LAS는 빔 서치(beam search) 알고리즘을 사용하며 디코딩 과정을 단계별로 간단히 정리하면 아래와 같다.
-
시작 토큰: 디코딩은 문장의 시작을 나타내는 시작 토큰(
<sos>)으로 시작하는 여러 부분 가설(partial hypotheses) 세트를 생성하면서 시작 -
가설 확장: 각 타임스텝에서, 세트에 있는 모든 부분 가설은 가능한 모든 다음 문자로 확장
-
빔 유지: 확장된 가설 중에서 가장 가능성이 높은 상위 β개의 가설만을 유지. 탐색 공간을 제한하고 계산 효율성 증대.
-
종료 토큰 처리: 문장의 끝을 나타내는 종료 토큰(
<eos>)이 가설 중 하나에 나타나면, 그 가설은 빔에서 제거되고 완성된 가설(complete hypothesis) 세트에 추가 -
선택적 사전 사용: 필요에 따라 사전을 사용하여 탐색 공간을 유효한 단어로만 제한한다. 하지만 모델이 대부분의 경우 실제 단어를 올바르게 철자를 사용하여 스펠링하는 것을 학습했기 때문에, 논문에서는 사전을 사용할 필요가 없다고 발견
Rescoring
beam 을 선택하는 공식은 아래와 같다.
| s는 스코어, | y | 는 나올 수 있는 y 값의 수, Plm(Y)는 언어모델이 예측하는 y 값 람다는 그것을 더하는 가중치 이다. |
Experiments
3백만 개의 Google 음성 검색 발화(2000 시간의 데이터). Youtube등으로 부터 데이터 등을 통해 노이즈를 섞어서 20배 양을 증가시켰다.
이를 40-dimensional log-mel filter bank 로 변경하고 10 ms 단위로 acoustic inputs 을 만들었다.
이중에서 16시간을 test data로 추출하여 검증을 했다. (train 과 같은 방식으로 뻥튀기)
텍스트는 전부 소문자로 바꾼 뒤 일부 구두점만 남기고 나머지는 다 특수 토큰으로 변경하여 사용.
3 layers of 512 pBLSTM nodes 을 사용하고 Asynchronous Stochastic Gradient Descent 를 적용하여 병렬 학습을 진행했다.
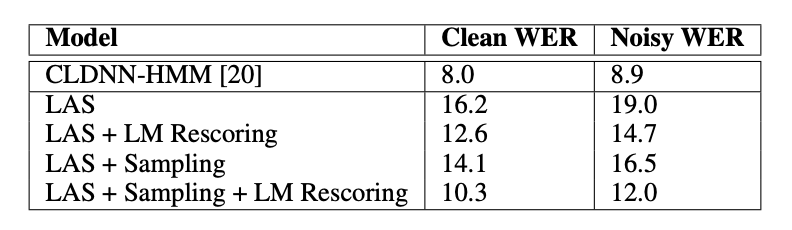
당시 state-of-the-art 인 CLDNN-HMM 은 8% WER 인 상황에서 LAS는 10.3% 정도로 우수한 점수를 냄.
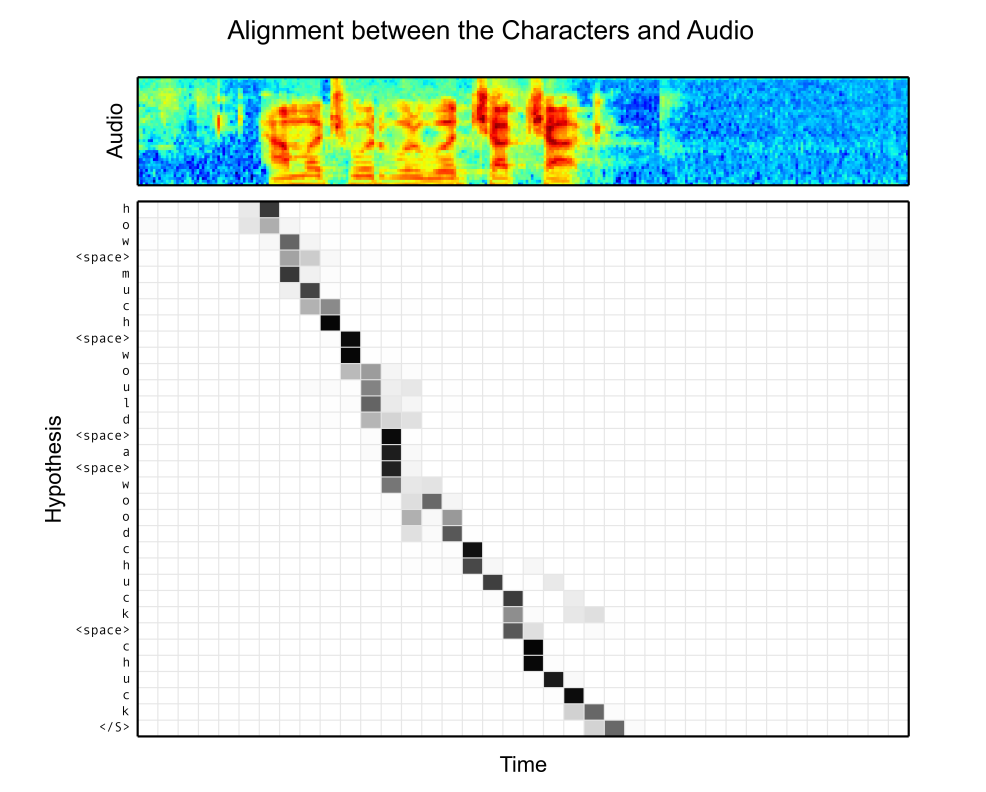
오디오와 텍스트가 Attention 을 통해 alignment 가 된 것을 표현. contents 기반 attention 이었지만 위치에 대해서 잘 파악하고 있기때문에
논문에서는 별도의 위치기반 Attention 은 필요가 없다고 판단했다.
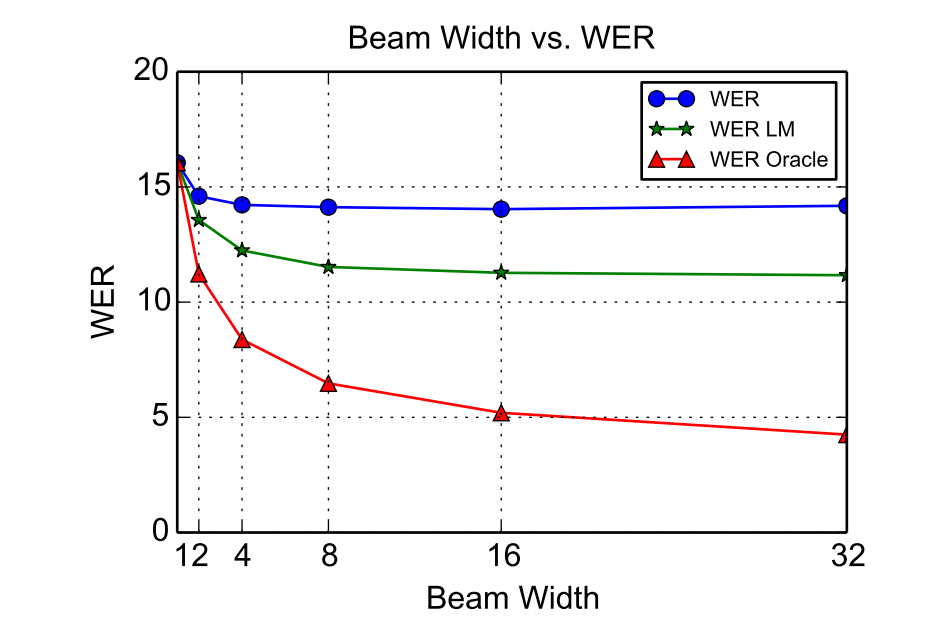
논문에서는 Beam 서치를 최대 32 로 하여 테스트를 진행했는데, 32일때 가장 좋은 성능을 내는것을 확인했다.
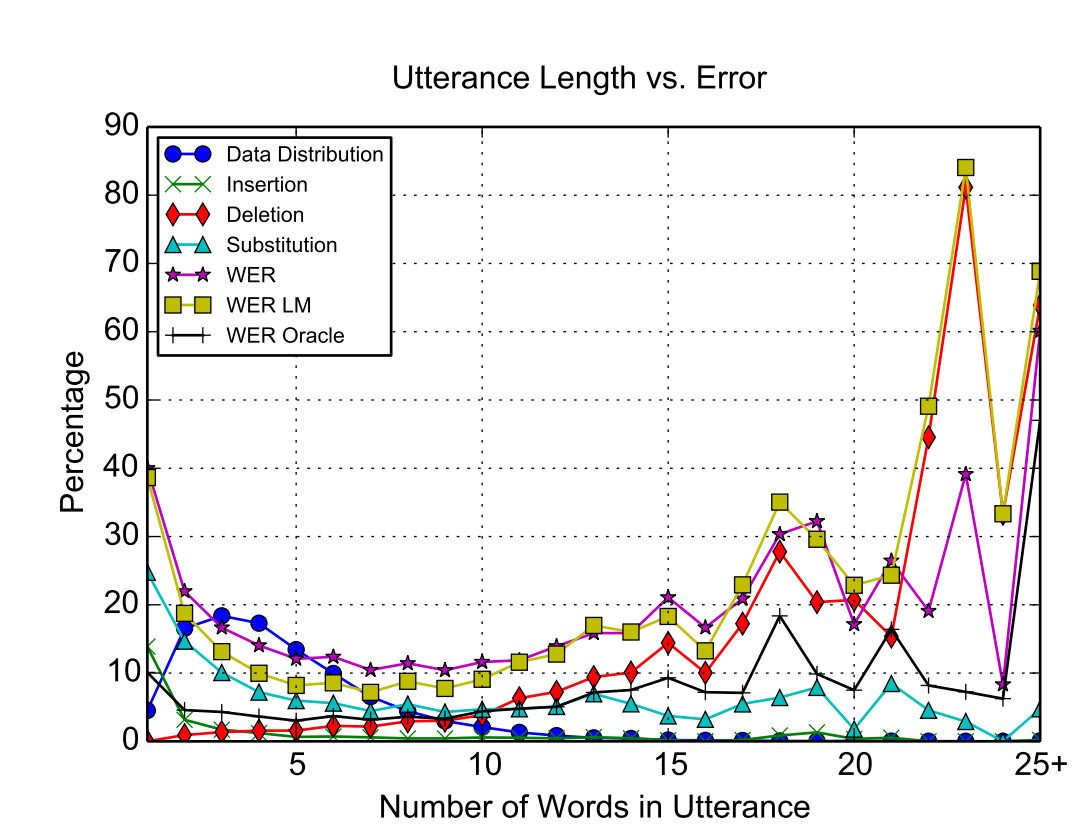
발화 과정 중에 단어수가 많게 되면 에러가 높아지는 것을 확인할 수 있다. 이때 에러의 종류는 단어를 삭제하는 Delete 가 많은것이 확인 된다.
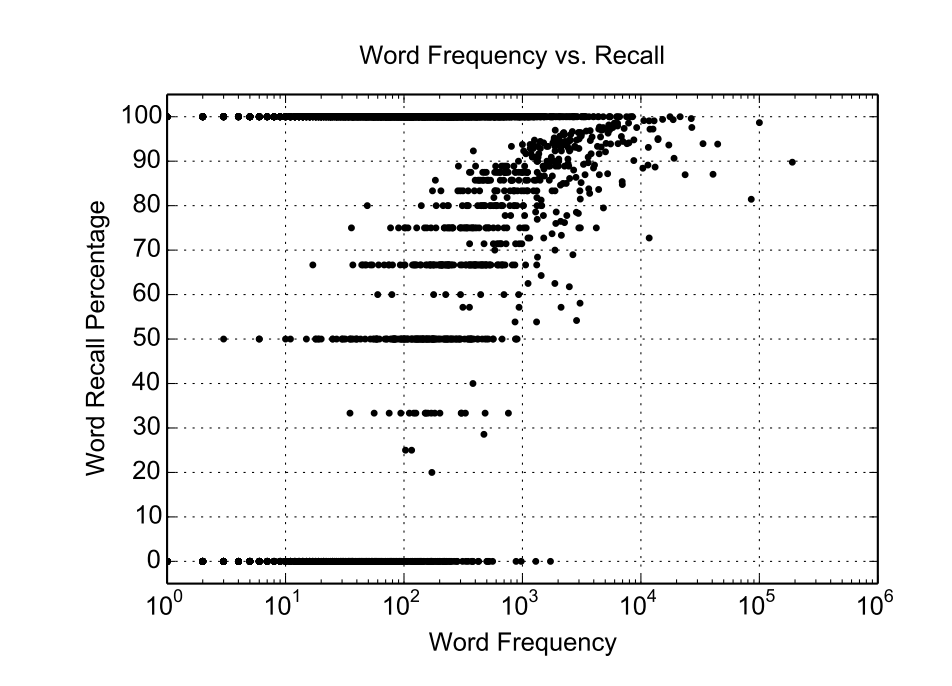
아무래도 많은 샘플이 있는 단어에 대해서 높은 Recall 이 나오는 것을 확인 할 수 있다. 다만 and 와 같이 자주 발생하는 단어에 대해서도 in에 대해 에러가 발생하는 것을 봐서, 많이 반복 되어도 특징이 있는 단어가 아니라면 오류가 있다는 것을 알 수 있다.

위에서 언급한것 처럼 컨텐츠 기반의 어텐션이지만 위치에 대해서 정확히 인지하고 있다는 것을 알 수 있다.

다만 Triple a라고 발음했음에도 불구하고 aaa 로 문맥적인 판단을 하는 것을 알 수 있다.
Conclusions
2016년 당시 개별 모델로 사용되던 ASR 환경을 attention을 사용한 end-to-end 모델로 새롭게 제시했고, 당시 state of arts 였던 CLDNN-HMM과
유사한 성능을 내는 것을 알 수 있었다.
Beam 에 사용되는 LM 에 따라 성능이 달라지긴 하지만, input과 output의 alignment 를 맞춰서 학습하는 모델에 대한 제시가 유의미했다고 볼 수 있다.

Comments