
Hbase Overview
Overview
이번 포스팅은 아파치 재단은(Apache) 재단의 nosql 데이터베이스인 hbase에 대해서 소개합니다.
구글의 nosql 데이터베이스인 빅테이블을 모델로하여 만들어진 hbase는 기본적으로 Key/Value 기반의 데이터베이스 입니다.
기본적으로 자바기반으로 구동되며 nosql 이기때문에 스킴에 제한 받지 않고 데이터를 저장할 수 있습니다.
또한 보편적인 rdms인 mysql 등과 다르게 로우 기반이 아닌 컬럼 단위의 데이터 저장을 합니다.
마지막으로 기존 rdbms 와 다르게 샤딩(sharding)에 굉장히 자유로운 구조이기 때문에 확장에 매우 용이합니다.
Table
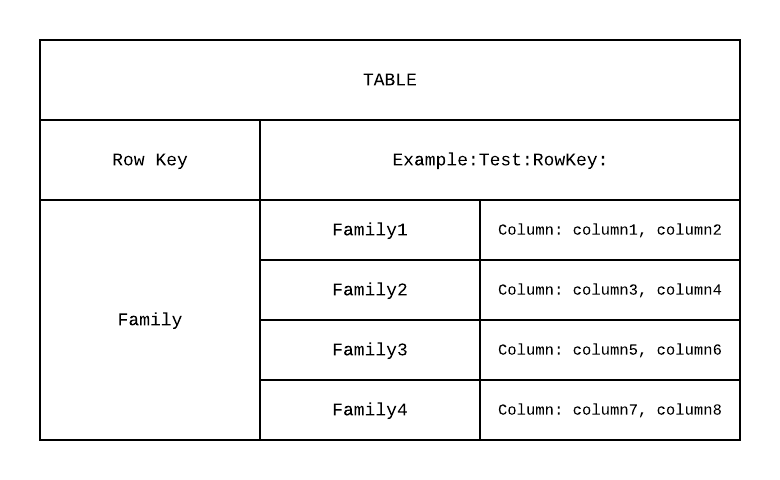
테이블은 위와 같은 형태로 저장됩니다.
Row Key가 rdbms의 primary 키와 동일하게 사용됩니다.
따라서 사용자는 row key를 이용하여 데이터 접근이 가능하며
컬럼 패밀리(column family), 컬럼(column) 순으로 접근하여 데이터를 읽을 수 있습니다.
hbase는 HDFS(Hadoop Distributed File System) 를 기반으로 동작하며
각각의 컬럼 패밀리는 하나 혹은 그이상이 모여 스토리지에 저장됩니다.
Architecture
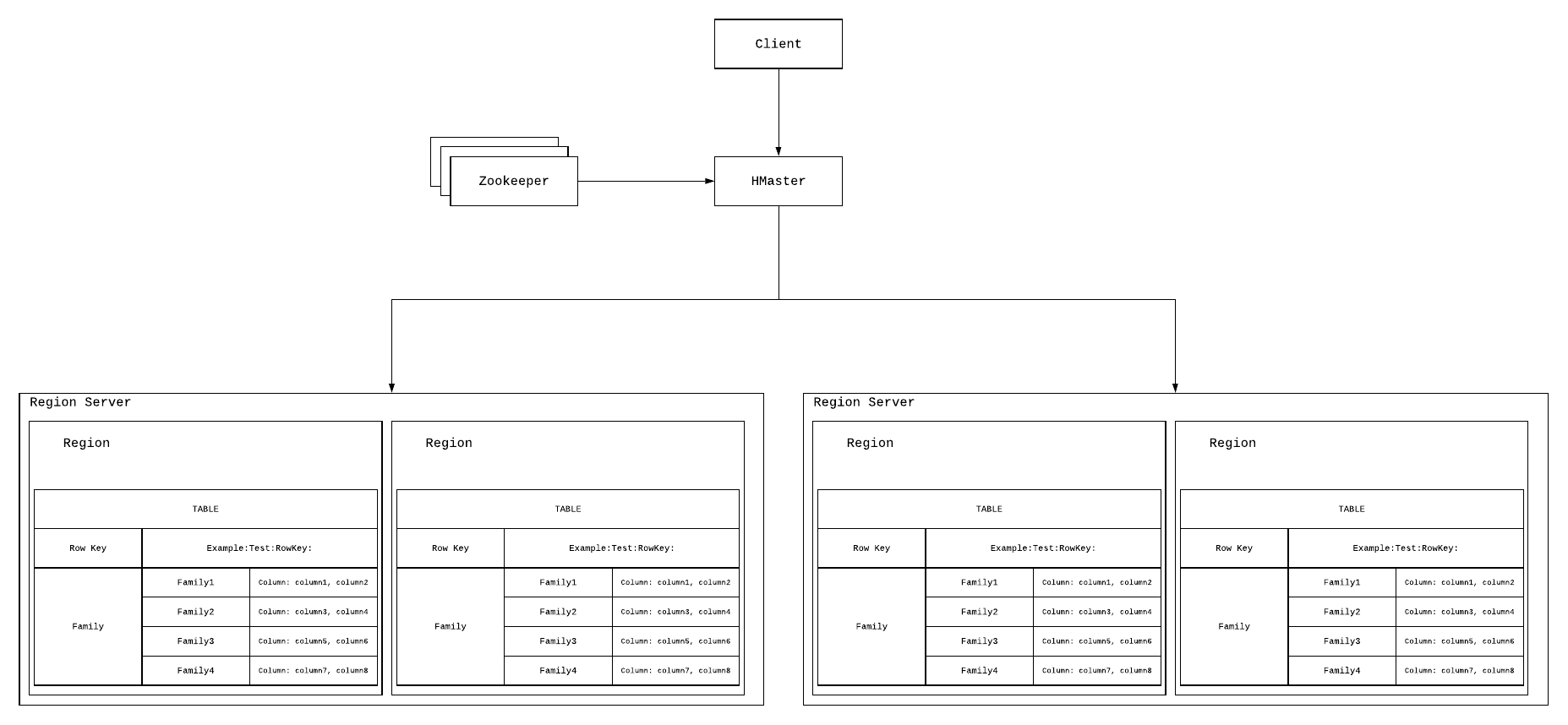
구조는 위와 같은 형태로 저장됩니다.
#MMaster
HMaster는 Region을 region 서버에 할당합니다. 즉 Region 서버들에 퍼저있는 region들의 로드밸런싱을 수행합니다.
또한 테이블 생성, column family 생성과 같은 DDL(Dasta Definition Language)를 담당합니다.
#Zookeeper
zookeeper는 hbase와 마찬가지로 아파치 재단의 오픈소스 프로젝트로 설정 정보를 관리, 분산처리를 동기화합니다.
클라이언트는 region과 통신하려면 반드시 zookeeper를 통과해야합니다.
따라서 hbase 를 이용하려면 zookeeper가 반드시 필요합니다.
#Resions Server
클라이언트와 통신을하고 데이터 연산을 처리합니다.
내부 region들의 크기관리, 읽기와 쓰기를 hdfs에 요청합니다.
사용하는 이유
컬럼 형태로 데이타가 저장되기 때문에, 동일한 속성의 데이터를 전체 조회하고 대량의 데이터 분석 처리 지원에 적합합니다.
중앙에 전체 분산 시스템을 통제하는 마스터를 두고 전체 데이터의 일관성을 관리하기때문에 샤딩과 같은 복제 데이터 사이의 일관성 보장합니다.

Comments