
Airflow에서 Selenium 사용하기
이번 블로그에서는 Selenium 을 이용한 웹 크롤링을 배우고 Airflow 에 적용하는 방법을 배워보겠습니다.
먼저 웹 크롤링에 대해서 설명하겠습니다.
웹 크롤링 이란
웹 크롤링이란 컴퓨터 소프트웨어 기술로 웹 사이트들에서 원하는 정보를 추출하는 것을 의미합니다.
다른 말로 ‘Web Scraping’ 이라고도 합니다.
웹 크롤링을 하려면 웹 페이지의 구조를 파악하고 있어야 합니다.
HTML
웹 페이지(web page)는 웹 상에 있는 개개의 문서를 가리킵니다. .gif, jpg 와 같은 확장자 포맷이 있듯이 HTML 은 .htm, .html 확장자 포맷을 가지고 있습니다.
이 html 문서는 단순히 텍스트 파일에 불과하고 웹 브라우저가 해석을 해서 구조를 통해 화면에 렌더링 해주게 되고 사용자는 View 라고 하는 스크린을 통해 접하게 되는 것입니다.
웹 브라우저가 html 파일을 해석하기 위해서는 형식에 맞게 html 파일이 작성되어 있어야 합니다. 이때 html 은 XML 이라고 불리는 포맷을 사용하여 구조화 되어 있습니다.
이 포맷의 가장 큰 특징은 Opening Tag와 Closing Tag를 갖고 있다는 것입니다.

이러한 Tag는 안에 My cat is very grumpy 와 같이 Text를 갖고 있을 수 있습니다.
<div><div>test</div></div>
또한 위와 같이 Tag 안에 다른 Tag를 포함 할 수 있습니다. 이러한 포함 관계를 이용하여 웹페이지는 Tag간의 계층구조를 갖게 되고 복잡한 웹페이지를 표현할 수 있게 됩니다.
HTML 의 구조
<html>
<head>
<meta/>
<link/>
<script></script>
</head>
<body>
</body>
</html>
위 형식은 Html의 기본 구조입니다. 우리는 웹 크롤링을 하기 위해서 웹페이지를 분석할 필요가 있습니다.
원하는 정보 찾기
원하는 정보가 포함되어있는 태그의 위치를 파악하기 위해서 우리는 Chrome 개발자를 이용합니다.
Chrome 개발자 도구는 HTML 의 위치를 우리가 보는 Rendering 된 View를 통해 손쉽게 찾을 수 있게 도와줍니다.
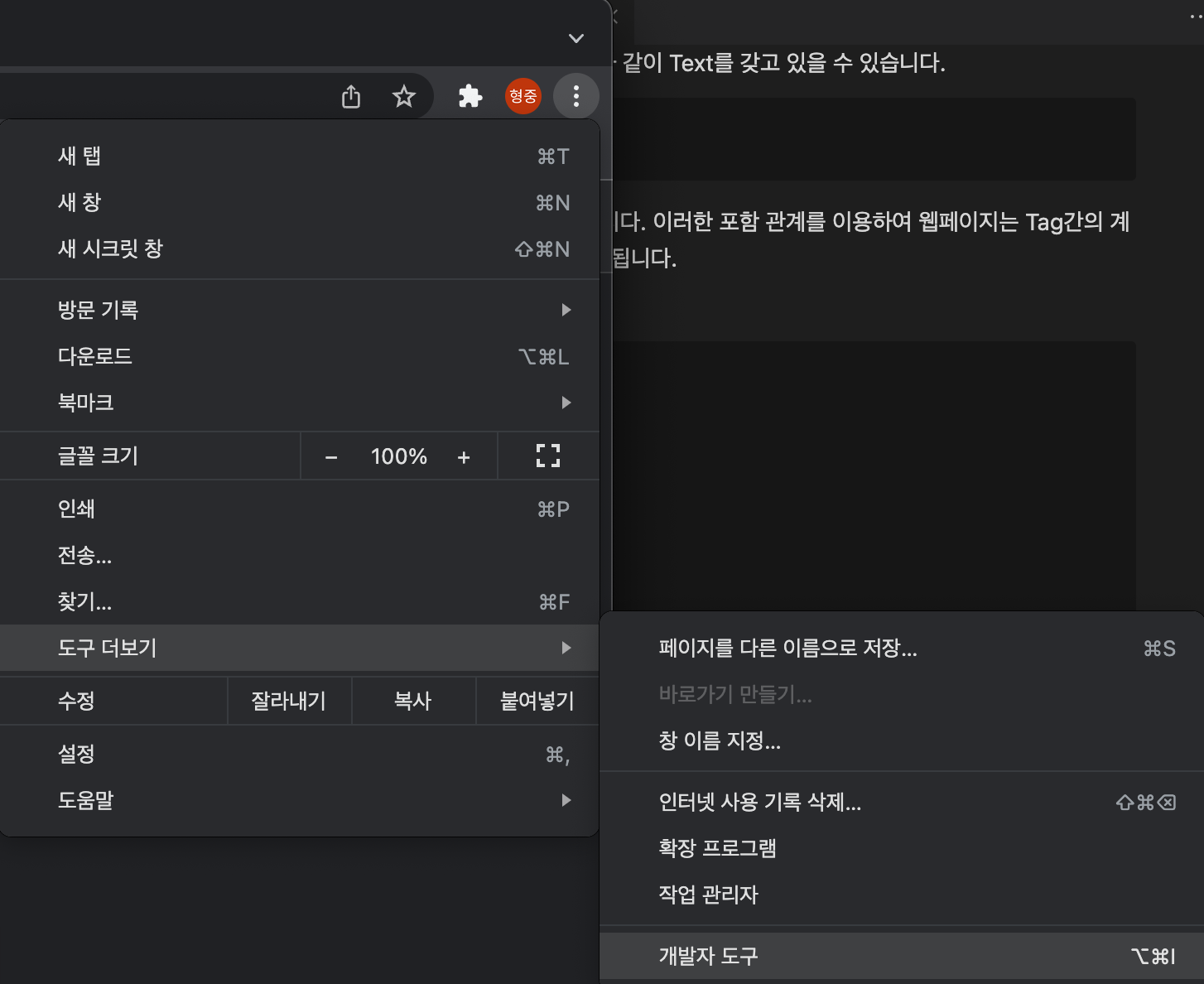
개발자 도구는 위 이미지와 같이 메뉴 -> 도구 더보기 -> 개발자 도구 를 이용하여 접근 할 수 있습니다.
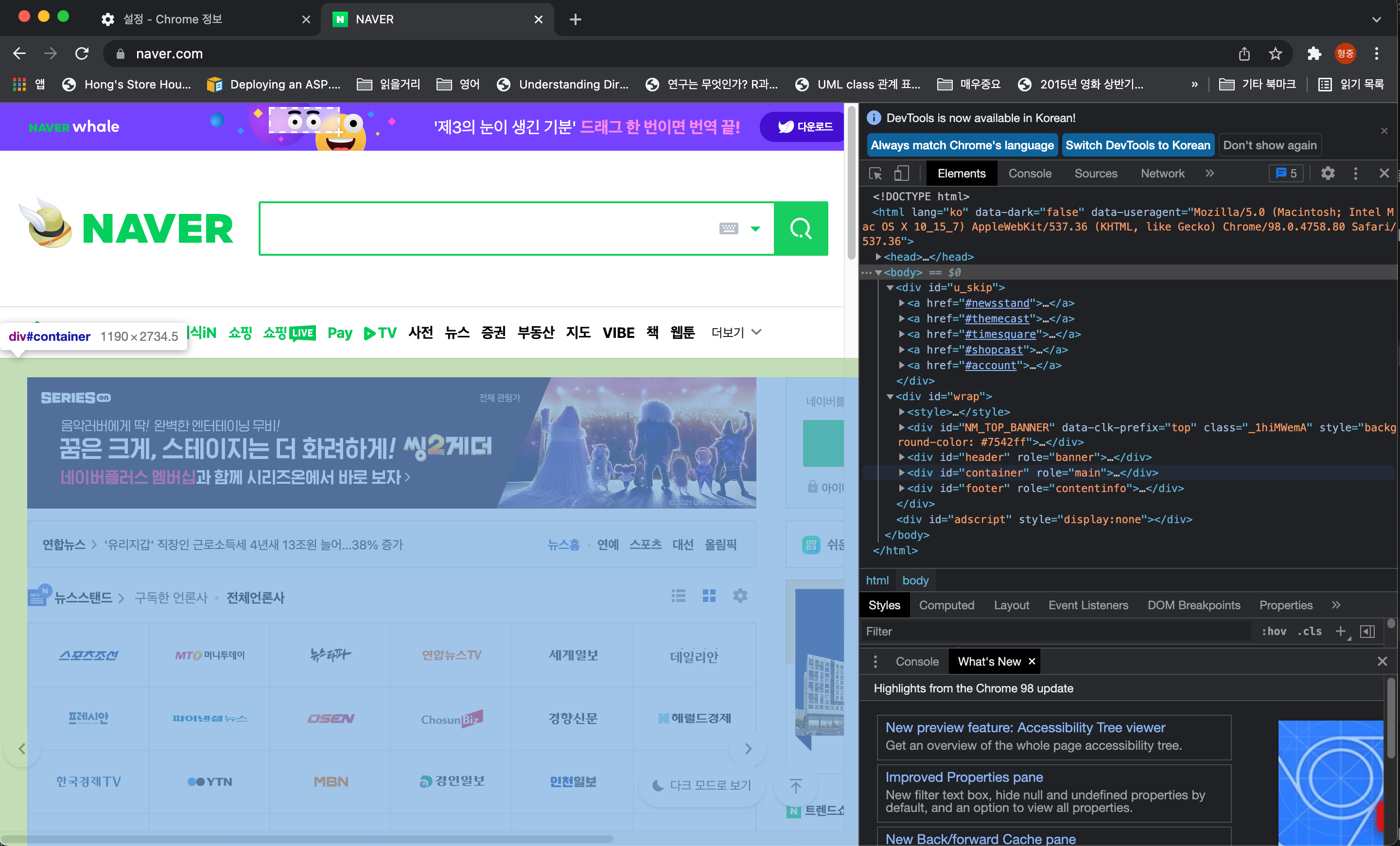
위 이미지에서 처럼 왼쪽 뷰에 마우스를 갖다대면 오른쪽의 HTML 영역에 위치를 알려줍니다.
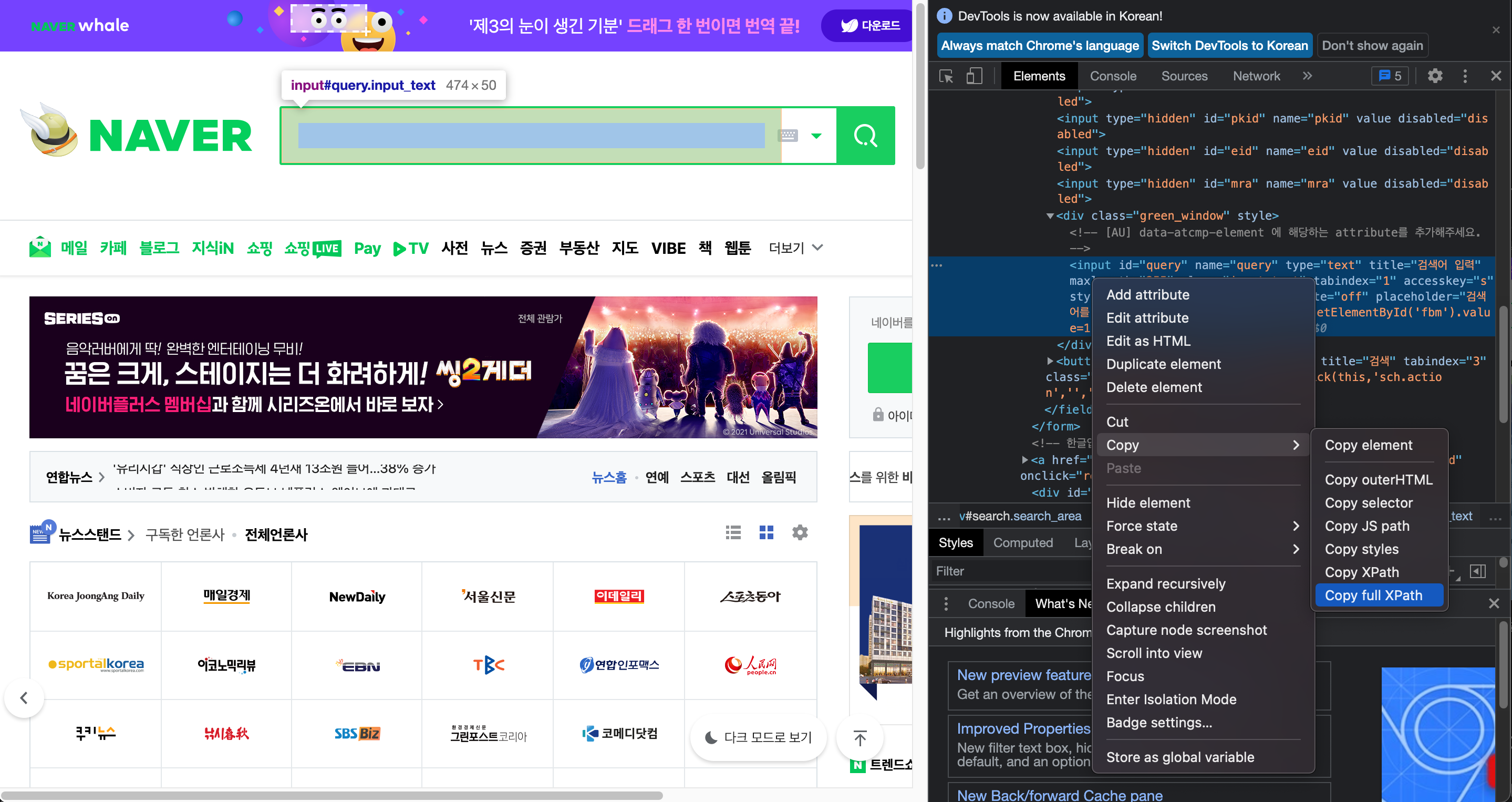
이때 오른쪽 HTML영역을 오른쪽 클릭하여 Copy -> Copy full path를 하게 되면 원하는 정보가 담겨있는 Tag의 주소를 획득 할 수 있습니다.
다른 크롤링 라이브러리와의 차이점
그렇다면 왜 Selenium 을 사용하는지 알아보겠습니다. 파이썬을 이용한 웹 크롤링 라이브러리는 Beautiful Soap, Scrapy 등 많은 라이브러리가 있습니다. 하지만 Selenium 을 사용하는 이유는 최근의 개발 환경은 HTML의 구조가 동적으로 계속 변경하기 때문입니다.
Beautiful Soap, Scrapy 은 서버로 부터 받은 첫번째 HTML만 크롤링이 가능하지만 Selenium 은 웹 브라우저에서 지속적으로 변경되는 HTML을 크롤링 할 수 있습니다.
이는 Selenium이 웹 드라이버를 이용해서 html와 자바스크립트 엔진을 이용해서 일반 웹 브라우저와 같이 동작하게 할 수 있기 때문입니다.
웹브라우저의 동작에 대해서 더 알고 싶다면 블로그 를 확인합니다.
Selenium 을 이용한 네이버 주식 페이지 크롤링
이제 Selenium을 이용해서 네이버 주식 페이지의 정보를 수집해 보겠습니다.
Selenium 설치
pip install selenium
Driver 다운로드
앞서 설명했던 것처럼 Selenium은 웹드라이버를 사용합니다. 자신의 컴퓨터에 설치되어있는 크롬의 버전을 확인하고 알맞는 버전을 다운로드합니다.
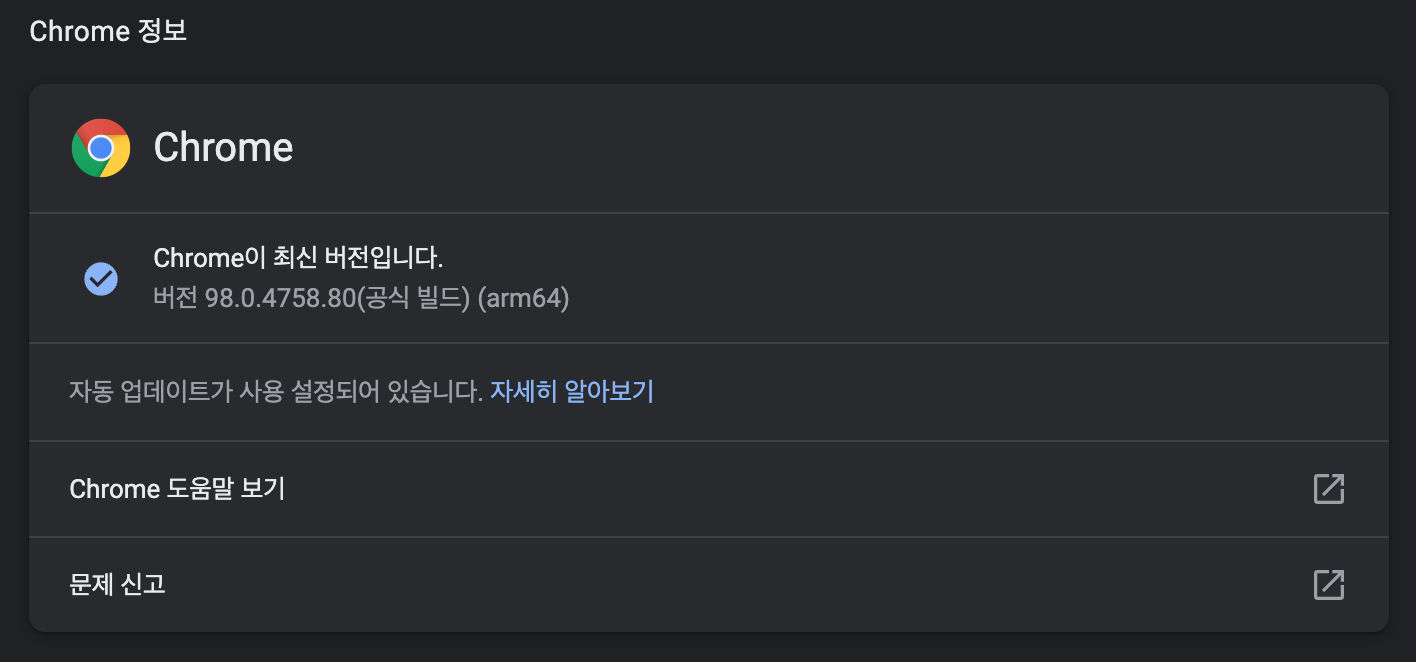
크롬 버전확인
크롬의 버전은 설정 -> Chrome 정보 에서 확인 할 수 있습니다.
버전에 맞는 드라이버 다운로드
https://chromedriver.chromium.org/downloads
코드 작성
이제 본격적으로 코드작성을 시작합니다.
드라이버 설정
신규로 작성할 파이썬 파일과 같은 경로에 다운로드 받은 chromedriver를 옮겨놓습니다. 임의의 위치에 옮겨놓고 python에서 특정 경로를 입력하는 방법도 있습니다. 본인에게 편한 방법을 사용합니다.
import selenium
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import time
s = Service('./chromedriver')
options = webdriver.ChromeOptions()
options.add_argument('window-size=1920x1080')
options.add_argument("disable-gpu")
options.add_argument("user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36")
driver = webdriver.Chrome(service=s, options=options)
selenium 관련 된 패키지를 임포트 합니다.
Service 클래스 객체를 chromedriver 의 경로를 넣고 생성합니다.
ChromeOptions 에 브라우저의 크기, gpu 사용여부, User agent 등의 정보를 넣습니다.
이후 driver = webdriver.Chrome(service=s, options=options) 를 통해서 driver 객체를 만듭니다. 이 driver 객체를 통해서 웹브라우저에 접근할 수 있게 됩니다.
네이버 주식 홈페이지 접근
드라이버에 get함수를 통해 특정 웹페이지에 접근 할 수 있습니다. 주식 정보를 획득 하기 위해 네이버 주식 홈페이지에 접근합니다.
driver.get('https://finance.naver.com/')
주식 코드 검색하기
주식을 검색하는 html 상의 위치를 찾습니다. 검색챙의 이름이 query로 되어있는 것으로 확인 할 수 있습니다. 이를 이용하여 접근합니다.
element의 이름으로 도큐먼트의 이름을 검색합니다.
search_box = driver.find_element(By.NAME,'query')
search_box.send_keys(code)
search_box.submit()
time.sleep(2)
이후 원하는 주식의 코드를 넣습니다. 이후 submit() 을 통해 검색을 진행합니다.
time.sleep(2) 을 사용합니다.
2초 동안 기다리는 이유는 실제 결과를 받고 화면상에 기다리는 시간을 넣기 위합니다.
결과값 갖고오기
주식 정보가 포함되어있는 HTML 문서를 확인합니다. 구조가 복잡하고 여러 Element가 동일한 규칙으로 되어있으므로 위에서 처럼 name으로 검색이 불가능합니다. 고유한 값인 XPath 를 이용하여 검색합니다.
company_name = driver.find_element(By.XPATH,"//*[@id='middle']/div[1]/div[1]/h2/a")
price = driver.find_element(By.XPATH,"/html/body/div[3]/div[2]/div[2]/div[1]/div[1]/div[1]/div/p[1]")
previous = driver.find_element(By.XPATH,"/html/body/div[3]/div[2]/div[2]/div[1]/div[1]/div[1]/div/p[2]")
stock_list.append(company_name.text)
stock_price.append(price.text.replace("\n", "").replace(",", ""))
stock_privous.append(previous.text.split("l")[1].replace("\n", "").replace("%", ""))
획득한 element의 text 값을 list에 저장합니다. 여기서 획득하는 값은 회사이름, 현재가격, 어제 값의 비교값입니다.
파일로 작성
결과를 확인하기위해 값을 파일에 넣습니다.
f = open("today_stock.txt", 'w')
for i, v in enumerate(code_list):
data = f'{v}\t{stock_list[i]}\t{stock_price[i]}\t{stock_privous[i]}\n'
f.write(data)
f.close()
전체 코드
전체코드는 아래와 같습니다.
import selenium
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import time
try:
s = Service('./chromedriver')
options = webdriver.ChromeOptions()
#options.add_argument('headless')
options.add_argument('window-size=1920x1080')
options.add_argument("disable-gpu")
options.add_argument("user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36")
driver = webdriver.Chrome(service=s, options=options)
code_list = ['005930', '005935', '004100', '035250', '018470', '039130', '006405', '066570', '003490']
stock_list=[]
stock_price=[]
stock_privous=[]
driver.get('https://finance.naver.com/')
for code in code_list:
search_box = driver.find_element(By.NAME,'query')
search_box.send_keys(code)
search_box.submit()
time.sleep(2)
company_name = driver.find_element(By.XPATH,"//*[@id='middle']/div[1]/div[1]/h2/a")
price = driver.find_element(By.XPATH,"/html/body/div[3]/div[2]/div[2]/div[1]/div[1]/div[1]/div/p[1]")
previous = driver.find_element(By.XPATH,"/html/body/div[3]/div[2]/div[2]/div[1]/div[1]/div[1]/div/p[2]")
stock_list.append(company_name.text)
stock_price.append(price.text.replace("\n", "").replace(",", ""))
stock_privous.append(previous.text.split("l")[1].replace("\n", "").replace("%", ""))
f = open("today_stock.txt", 'w')
for i, v in enumerate(code_list):
data = f'{v}\t{stock_list[i]}\t{stock_price[i]}\t{stock_privous[i]}\n'
f.write(data)
f.close()
finally:
driver.quit()
실행결과
today_stock.txt 에 작성 된 내용을 확인해봅니다.
005930 삼성전자 74900 -0.66
005935 삼성전자우 68900 -0.14
004100 태양금속 1700 +29.77
035250 강원랜드 26700 +3.09
018470 조일알미늄 2220 -1.33
039130 하나투어 78800 +0.51
006405 삼성SDI우 300000 -1.96
066570 LG전자 126500 -1.56
003490 대한항공 30150 -0.33
Headless 설정
위 코드를 돌려보면 크롬이 동작하는 것을 화면상에서 계속 확인 할 수 있었습니다. 개발 할 때는 편리하지만 개발 완료 후 지속적인 수집을 위해서는 화면에 보이는 것이 방해 됩니다. Headless 설정을 통해 화면에 보이지 않게 할 수 있습니다.
s = Service('./chromedriver')
options = webdriver.ChromeOptions()
options.add_argument('headless')
options.add_argument('window-size=1920x1080')
options.add_argument("disable-gpu")
options.add_argument("user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36")
driver = webdriver.Chrome(service=s, options=options)
Airflow 에 적용하기
이제 selenium을 통한 크롤링을 airflow 에서 구동되게 해보겠습니다.
- airflow/plugin/operator 경로에 chromedriver 를 옮깁니다.
- operator 파일을 생성합니다.
import selenium
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import time
from airflow.models import BaseOperator
class StockCrawlingOperator(BaseOperator):
def __init__(self, code_list, *args, **kwargs):
self.code_list = code_list
super().__init__(*args, **kwargs)
def execute(self, context):
try:
s = Service('./chromedriver')
options = webdriver.ChromeOptions()
#options.add_argument('headless')
options.add_argument('window-size=1920x1080')
options.add_argument("disable-gpu")
options.add_argument("user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36")
driver = webdriver.Chrome(service=s, options=options)
stock_list=[]
stock_price=[]
stock_privous=[]
driver.get('https://finance.naver.com/')
for code in self.code_list:
search_box = driver.find_element(By.NAME,'query')
search_box.send_keys(code)
search_box.submit()
time.sleep(2)
company_name = driver.find_element(By.XPATH,"//*[@id='middle']/div[1]/div[1]/h2/a")
price = driver.find_element(By.XPATH,"/html/body/div[3]/div[2]/div[2]/div[1]/div[1]/div[1]/div/p[1]")
previous = driver.find_element(By.XPATH,"/html/body/div[3]/div[2]/div[2]/div[1]/div[1]/div[1]/div/p[2]")
stock_list.append(company_name.text)
stock_price.append(price.text.replace("\n", "").replace(",", ""))
stock_privous.append(previous.text.split("l")[1].replace("\n", "").replace("%", ""))
f = open("today_stock.txt", 'w')
for i, v in enumerate(self.code_list):
data = f'{v}\t{stock_list[i]}\t{stock_price[i]}\t{stock_privous[i]}\n'
f.write(data)
f.close()
finally:
driver.quit()
- Dag 파일을 생성합니다.
from datetime import datetime, timedelta
from airflow import DAG
from operators.stock_crawling_operator import StockCrawlingOperator
from operators.slack_webhook_operator import SlackWebhookOperator
from utils.slack import slack_success_alert
from utils.slack import slack_fail_alert
with DAG(
dag_id='crawling_test_dag',
schedule_interval='0 * * * *',
start_date=datetime(2021, 1, 1),
catchup=False,
dagrun_timeout=timedelta(minutes=60),
tags=['mongo'],
default_args={
'on_success_callback': slack_success_alert,
'on_failure_callback': slack_fail_alert
},
params={
},
) as dag:
t1 = StockCrawlingOperator(task_id='stock_crawling_task',
code_list=['005930', '005935', '004100', '035250', '018470', '039130', '006405', '066570', '003490'],
dag=dag)
#https://vip.mk.co.kr/newSt/rate/best.php?gubn=kospi 에서 코드 갖고오는 것 숙제!
#Mysql에 추가하는 코드 숙제!
t1
if __name__ == "__main__":
dag.cli()
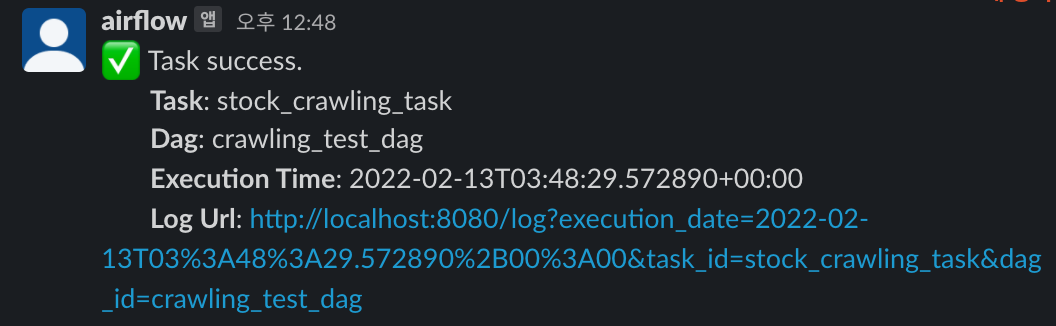
- 결과를 확인합니다.

Comments