
Data Pipeline
서비스에서 발생하는 Data가 어떤 과정을 통해 전달 되는지에 대해 설명합니다.
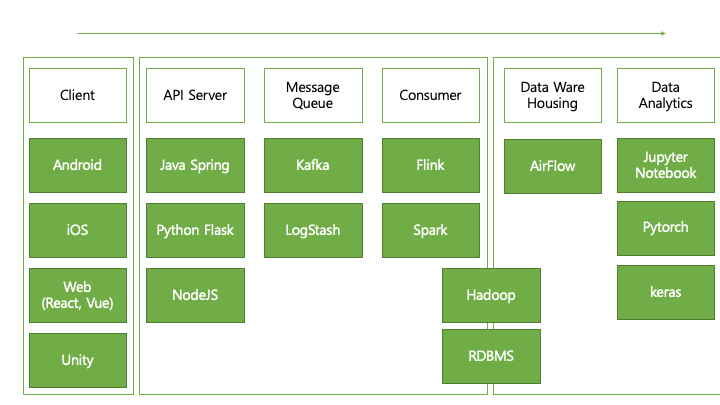
데이터는 주로 사용자가 사용하는 클라이언트에서 발생해서 API 서버로 전달 됩니다.
클라이언트의 종류는 Android, iOS와 같은 모바일 환경, React, Vue 등으로 만들어진 Web Page, Unity로 만들어진 Game등 다양한 종류가 있습니다.
클라이언트가 다양한 만큼 데이터의 형태도 매우 다양하고, 전달하는 방식도 매우 다양하지만 주로 Json(JavaScript Object Notation) 형태로 전달됩니다.
그리고 데이터가 포함된 JSON은 HTTP API를 통해 서버로 전달됩니다.
서버는 Json 데이터를 받아서 데이터베이스에 저장해야합니다. 이때 데이터의 저장이 빈번하고 많으면 데이터베이스와 서버에 부하가 걸려 즉시 저장할 수 없으므로 따로 파일로 저장하거나 Message Queue에 데이터를 임시 저장합니다.
이러한 역할을하는 framework는 kafka와 logstash가 있습니다.
임시 저장된 데이터는 정제 과정을 거쳐 이제 데이터베이스에 저장됩니다. 최근 취급되는 데이터는 형태와 양이 매우 커서 Hadoop 과 같은 분산처리 데이터베이스에 저장됩니다. 데이터의 무결성이 중요한 경우 RDBMS에 저장됩니다.
이렇게 저장 된 데이터는 Raw Data라고하며 지금의 형태는 분석하기에 아주 좋은 형태는 아닙니다. 그래서 데이터를 사용하기 좋게 변경을 해야합니다. 이러한 과정을 Data Warehousing 이라고 하며 생성 된 데이터 테이블은 Data Mart라고 불립니다.
정리 된 Data Mart를 통해 분석가들은 데이터 분석을 진행하며 파이토치, 케라스 등을 이용하여 머신러닝 기법을 적용 분석하기도 합니다.

Comments