
HUE

What is HUE?
Hue(Haddop User Experience)는 Apache Haddop 클러스터와 함께 사용되는 웹 기반 인터페이스입니다. Hue는 다른 Hadoop 에코시스템과 함께 사용가능하며 Hive, Impla, HDFS, Spark등 여러 시스템을 UI로 제공합니다.
Feature
- Document: Hue에서 저장한 Workflow, 쿼리, 스크립트 파일을 볼 수 있습니다.
- File: HDFS에 저장된 파일을 볼 수 있습니다.
- Table: Hive Warehouse에 저장된 테이블을 볼 수 있습니다.
- Job: 실행한 Job의 상태, 로그를 볼 수 있습니다.
- Security : Sentry Table, 파일 ACL등을 설정할 수 있습니다.
HDFS Browser
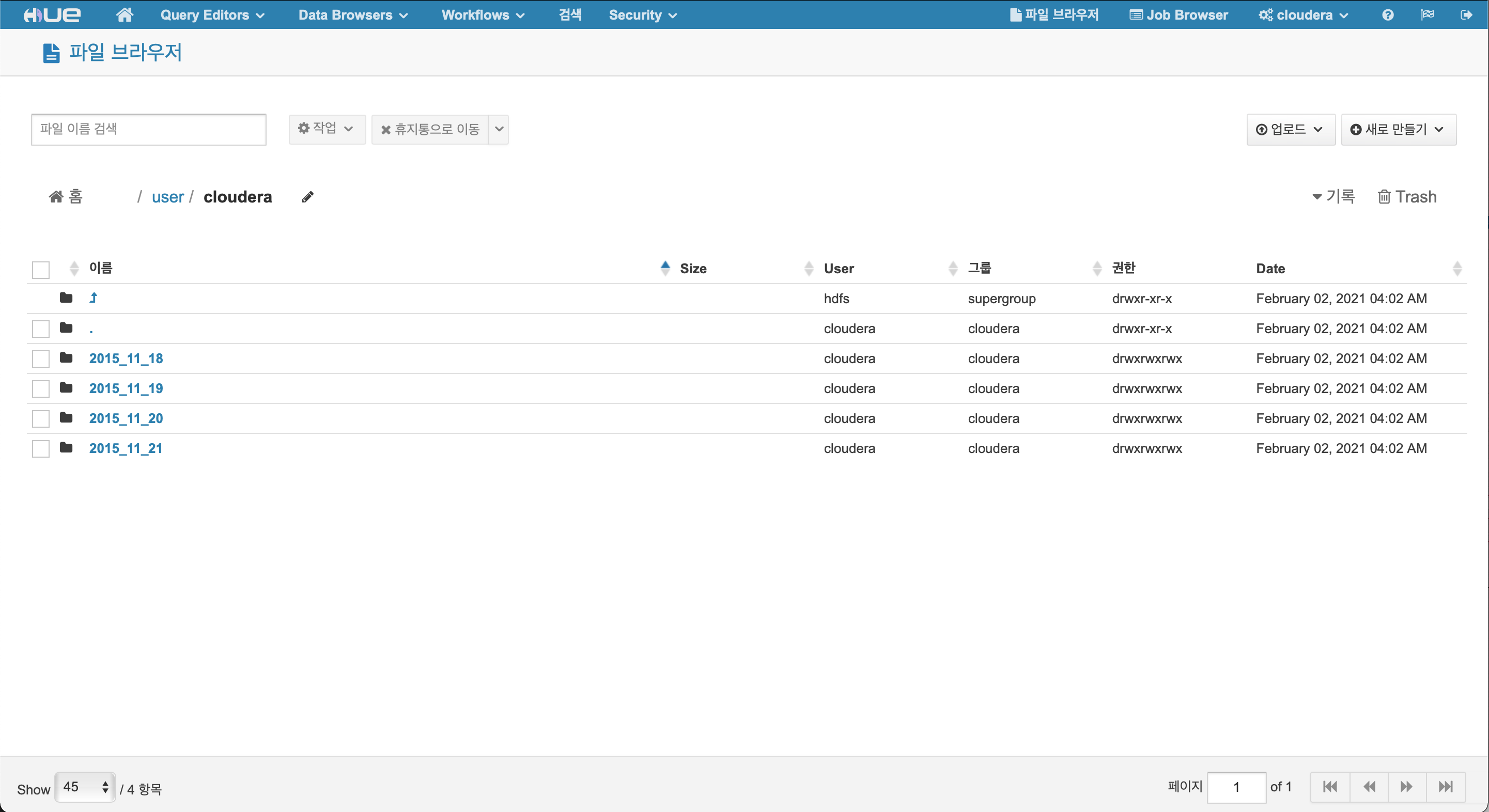
Feature
- 파일 경로 조회를 할 수 있습니다.
- 이름 변경, 이동, 삭제 등을 할 수 있습니다.
HIVE Editor
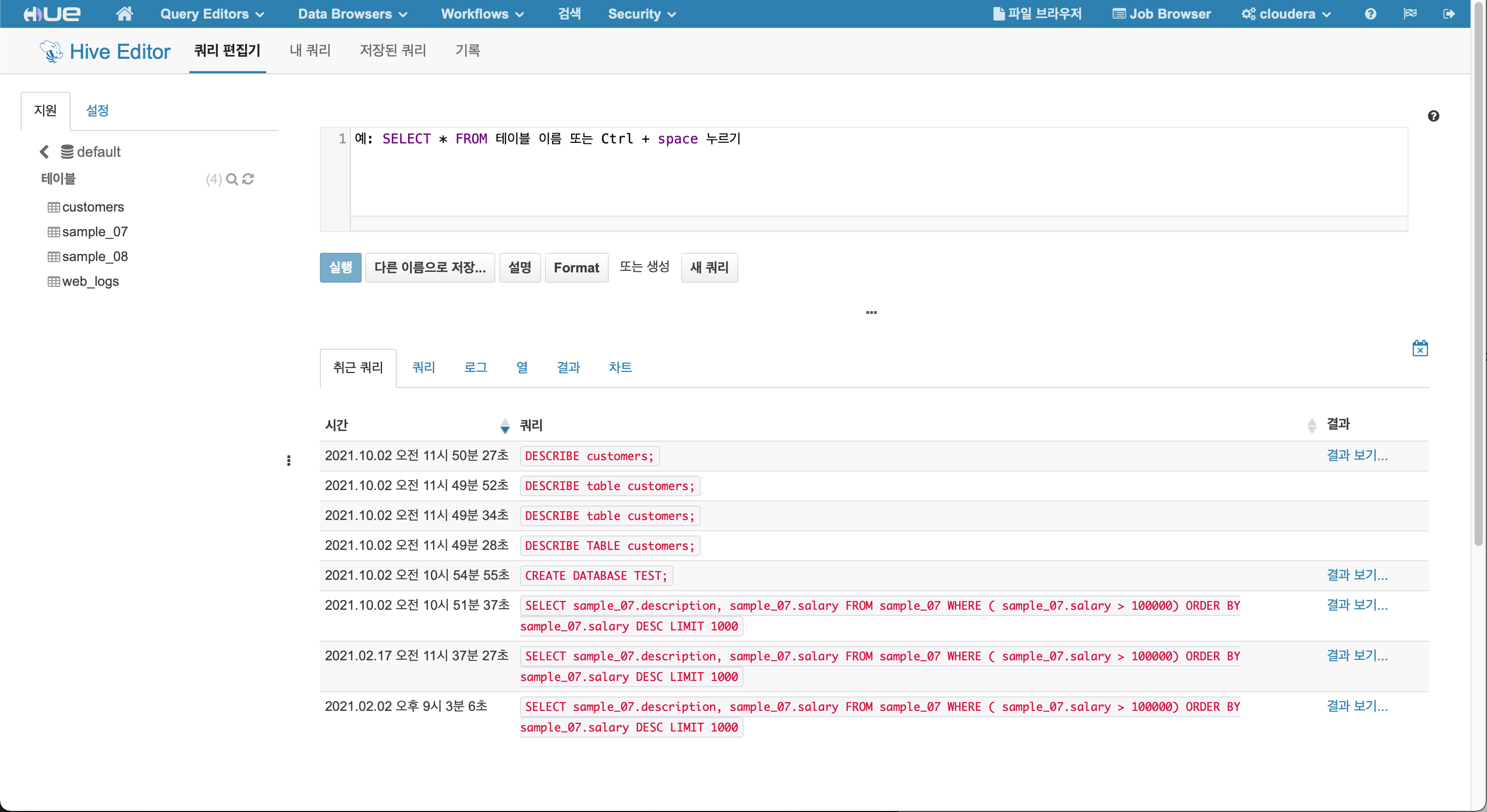
Feature
- Database 조회, 생성할 수 있습니다.
- Table 조회, 생성, 수정할 수 있습니다.
- Query 조회, 결과를 확인 할 수 있습니다.
Impla Editor
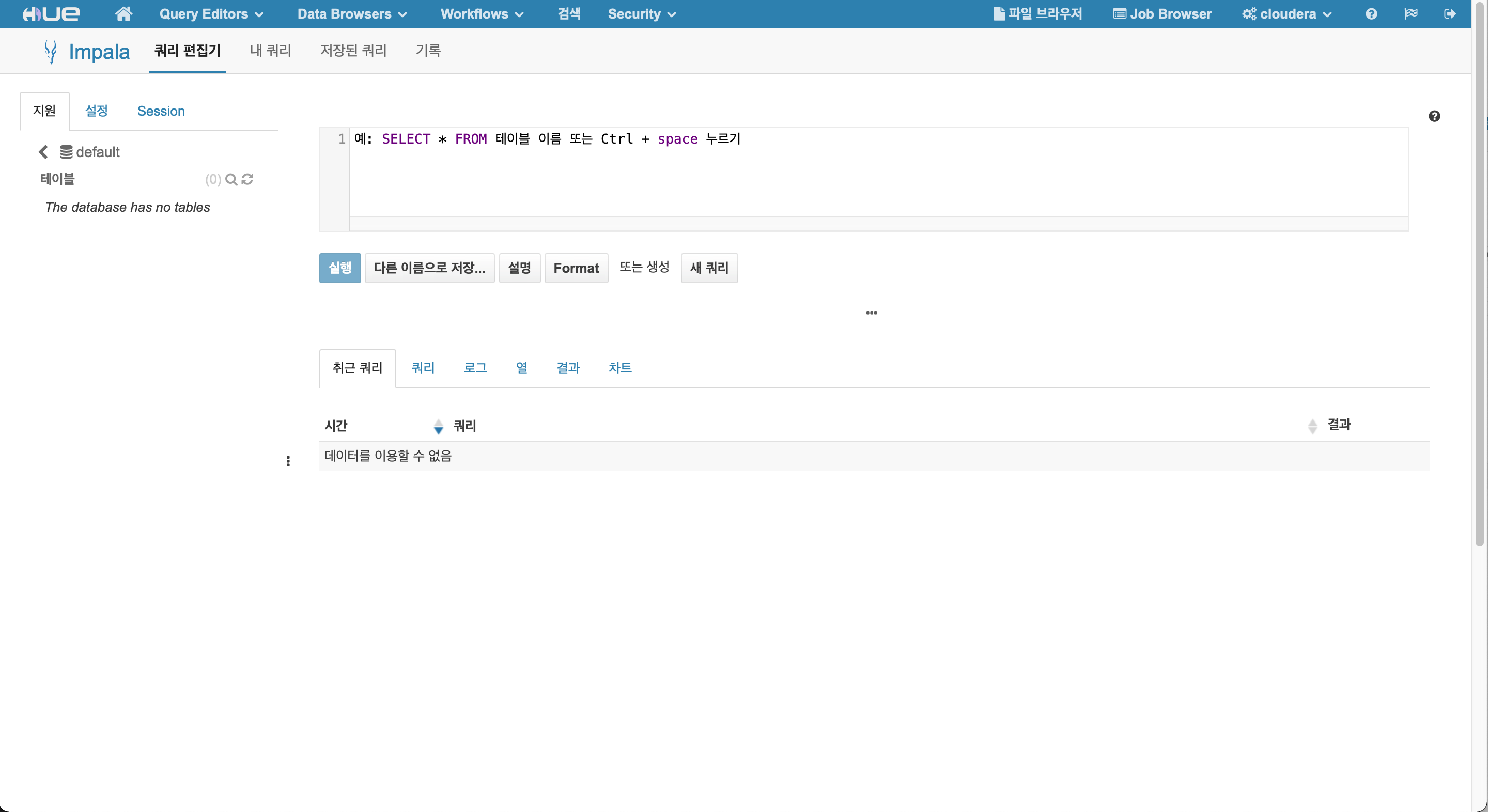
- Database 조회, 생성할 수 있습니다.
- Table 조회, 생성, 수정할 수 있습니다.
- Query 조회, 결과를 확인 할 수 있습니다.
Job Browser
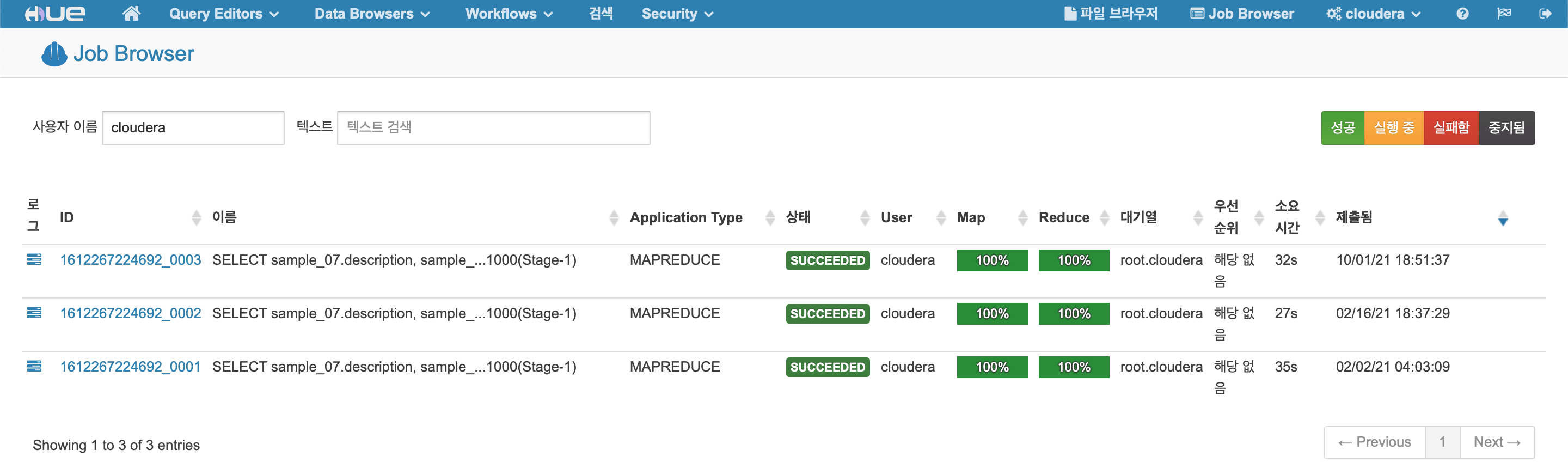
HIVE
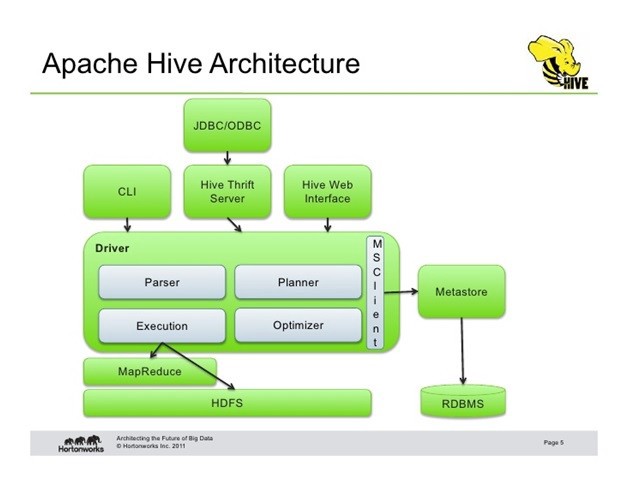
HIVE Case Study
Create Data Table From HDSF
CREATE EXTERNAL TABLE `log`(
`logid` string,
`created` string,
`userkey` string,
`os` string,
`servicecode` string,
`value` string,
`dimensions` string)
PARTITIONED BY (
`dt` string,
`svc` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim'='\t',
'line.delim'='\n',
'serialization.format'='\t')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://test/user/test/log'
select
SELECT
A.dt,
A.country,
count(DISTINCT A.userkey) as user_count,
FROM log A
LATERAL VIEW json_tuple(A.dimensions, 'reqPath', 'resHttpStatusCode', 'resBody') d0
as reqPath, resHttpStatusCode, resBody
LATERAL VIEW json_tuple(d0.resBody, 'use', 'balance') d1
as use, balance
LATERAL VIEW json_tuple(d1.use, 'test1', 'test2', 'test3', 'test4', 'test5') d2
as test1, test2, test3, test4, test5
where svc in ('test_svc') and '20210920' <= dt and dt <= '20210922'
and d0.resHttpStatusCode = '200'
group by A.dt,
A.country
order by dt
Column based
https://nesoy.github.io/articles/2019-10/Column-Oriented-DBMS
Column based encoding format
- What is column based encoding format
- ORC developed by Hotonworks Optimized for Hive (generally) https://orc.apache.org/
- Parquet developed by Cloudera, Twitter based on https://research.google/pubs/pub36632/ https://parquet.apache.org/ https://www.slideshare.net/larsgeorge/parquet-data-io-philadelphia-2013
- Performance comparison : Parquet vs ORC https://www.slideshare.net/HadoopSummit/file-format-benchmark-avro-json-orc-parquet https://www.datanami.com/2018/05/16/big-data-file-formats-demystified/ https://medium.com/@dhareshwarganesh/benchmarking-parquet-vs-orc-d52c39849aef
ORC(Optimized Row Columnar) 파일 포맷
ORC 파일 포맷은 하이브의 처리 속도를 높이기 위하여 개발 되었습니다.
하이브가 처음에 사용한 TextFile, SequenceFile 포맷의 처리속도를 높이기 위하여 RCFile 포맷이 개발 되었습니다. RCFile 포맷은 각 컬럼을 하나의 파일 묶음으로 만들었기 때문에 각 노드에 분산 처리된 데이터를 모으는 비용이 많이 들어가게 됩니다. 이를 극복하기 위하여 제안된 것이 ORC 파일 포맷입니다. ORC 포맷은 칼럼 단위로 데이터를 기록하고, 인덱스를 기록하여 컬럼에 바로 접근할 수 있기 때문에 속도가 빨라집니다.
ORC 포맷은 호튼웍스의 부사장 오웬오말리가 제안한 것으로 하나의 파일에 칼럼을 json 처럼 중첩구조로 구성할 수 있고, 리스트, 맵과 같은 복합형태로 구조를 가져갈 수 있기 때문에 오픈 소스 진영에서 많은 관심을 받고 있습니다.
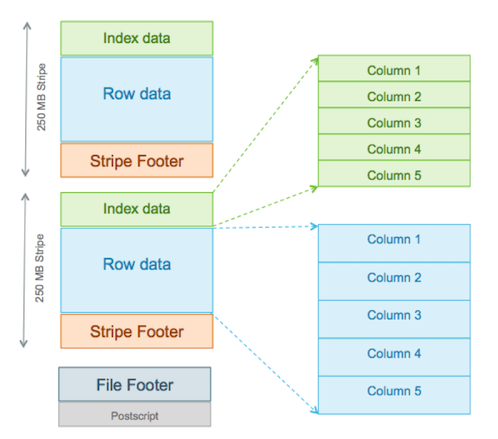
feature
- 각 태스크의 결과가 하나의 파일로 생성됨: 네임노드의 부하를 줄여줌
- datetime, decimal, complex type(struct, list, map, union)을 지원
- 파일에 경량 인덱스가 저장됨
- 파일 경량 인덱스가 저장됨
- 필터링 조건이 없는 로우 그룹은 스킵
- 특정 row 로 seek 가능
- 데이터 타입 기반의 block-mode 압축
- integer 컬럼은 run-length encoding 을 사용
- 문자열 컬럼은 dictionary enocding 을 사용
- 하나의 파일을 여러개의 리더로 동시 읽기 가능
- 마커 스캐닝 없이 파일 분할 가능
- 파일 읽기 쓰기에 일정한 메모리 용량만 필요
- 필드의 추가나 제거가 가능한 메타 데이터는 Protocol Buffers 를 사용해서 저장
case study
CREATE TABLE table1 (
col1 string,
col2 string
) STORED AS ORC
TBLPROPERTIES (
"orc.compress"="ZLIB",
"orc.compress.size"="262144",
"orc.create.index"="true",
"orc.stripe.size"="268435456",
"orc.row.index.stride"="3000",
"orc.bloom.filter.columns"="col1,col2"
);
ORC 설정 값
- orc.compress 기본값: ZLIB 압축방식 설정 (one of NONE, ZLIB, SNAPPY)
- orc.compress.size 기본값: 262,144 압축을 처리할 청크 사이즈 설정(256 * 1024 = 262,144)
- orc.create.index 기본값: true 인덱스 사용 여부
- orc.row.index.stride 기본값: 10,000 설정 row 이상일 때 인덱스 생성 (must be >= 1000)
- orc.stripe.size 기본값: 67,108,864 스트라이프를 생성할 사이즈 (64 * 1024 *1024 = 67,108,864)), 설정 사이즈마다 하나씩 생성
- orc.bloom.filter.columns 기본값: “” 블룸필터1를 생성할 컬럼 정보, 콤마(,)로 구분하여 입력
- orc.bloom.filter.fpp 기본값: 0.05 블룸필터의 오판 확률(fpp=false positive portability) 설정 (must >0.0 and <1.0)
Parquet
CREATE TABLE test(a int, b string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS PARQUET TBLPROPERTIES ("parquet.compression"="SNAPPY");
Impla
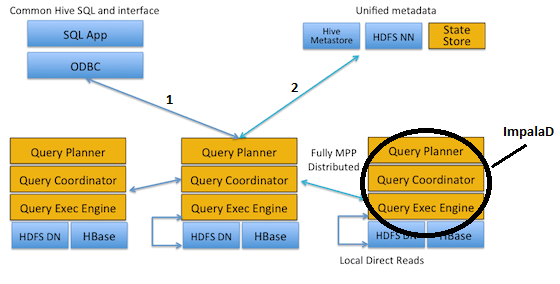
Sequence
- 클라이언트가 직접 Impalad(프로세스)에 요청을 보냅니다.
- Impalad가 Hive MetaStore 및 HDFS NameNode 에서 메타 데이터를 가져옵니다.
- Impalad가 State store에서 데이터가 있는 다른 Impalad의 상태를 가져옵니다.
- 이후 Impalad는 클라이언트로부터 받은 쿼리 실행을 시작합니다.
Important points
- MapReduce를 사용하지 않습니다.
- Impala에서는 하이브의 테이블을 사용할 수 있습니다. 일반적으로 Hive, Impala를 동시에 사용하는것이 보통이므로 Impala에서만 테이블을 생성하는경우는 거의 없다. <- 초기 버전은 impala가 직접 테이블을 생성 못했습니다.
- Impalad는 빠른 액세스를 위해 메타 데이터를 캐시합니다.
- 일반적으로 catalogd를 통해 메타데이터가 업데이트가 되면 아무런 문제가 없지만, 외부데이터 (HDFS, Hive, …)의 변동사항으로 데이터가 변하면 refresh, invalidate metadata등을 수행할 필요가 있다.
- Impala는 parquet 형식에 가장 적합합니다.
- Impala는 OS 캐시를 사용합니다.
- 메모리에 쿼리의 중간결과를 저장합니다.
- 메모리 의존도가 매우 큽니다.
- 각 노드에 128GB RAM 권장합니다. (Cloudera 권장)
- 일반적으로 FS에 중간결과를 저장하는 Hive에 비해 5배-100배 가량 수행속도가 빠릅니다.
https://d2.naver.com/helloworld/246342
reference
https://data-science-hi.tistory.com/23 https://118k.tistory.com/408

Comments