
Hadoop
Big Data
빅 데이터란 양(volume)이 매우 많고, 증가 속도(velocity)가 빠르며, 종류(variety)가 매우 다양한 데이터를 말합니다. 이것을 3V라고도 합니다.
간단히 말해, 빅 데이터는 특히 새로운 데이터 소스에서 나온 더 크고 더 복잡한 데이터 세트입니다. 이러한 데이터 세트는 너무 방대하여 기존의 데이터 처리 소프트웨어로는 관리할 수 없습니다. 그러나 이러한 방대한 양의 데이터는 이전에 해결할 수 없었던 비즈니스 문제를 해결하는 데 사용될 수 있습니다.
빅데이터의 3대 요소 3V
| Name | Desc |
|---|---|
| volume | 데이터의 양이 중요합니다. 빅 데이터를 사용하면 저밀도 비정형 데이터를 대량으로 처리해야 합니다. Twitter 데이터 피드, 웹 페이지나 모바일 앱의 클릭 스트림, 센서 지원 장비와 같이 알려지지 않은 값의 데이터가 여기에 해당될 수 있습니다. 일부 조직의 경우, 데이터 양이 수십 테라바이트가 될 수 있습니다. 아니면 수백 페타바이트가 될 수 있습니다. |
| velocity | 속도는 데이터가 얼마나 빨리 수신 및 처리되는가를 나타냅니다. 일반적으로 데이터를 디스크에 기록하는 것보다 메모리로 직접 스트리밍할 때 속도가 가장 빠릅니다. 일부 인터넷 지원 스마트 제품은 실시간 또는 거의 실시간으로 작동하기 때문에 실시간 평가 및 조치가 필요합니다. |
| variety | 종류란 사용 가능한 데이터의 유형 수를 나타냅니다. 전통적인 데이터 유형은 정형화되어 관계형 데이터베이스에 적합했습니다. 빅 데이터의 등장으로 새로운 비정형 유형의 데이터가 나타났습니다. 텍스트, 오디오 및 비디오 같은 비정형 및 반정형 데이터 유형은 의미를 도출하고 메타 데이터를 지원하기 위해 추가로 전처리가 필요합니다. |
Hadoop
Google BigTable (2006)을 기본으로하여 아파치 재단에서 관리하는 빅데이터 환경입니다.
HDFS
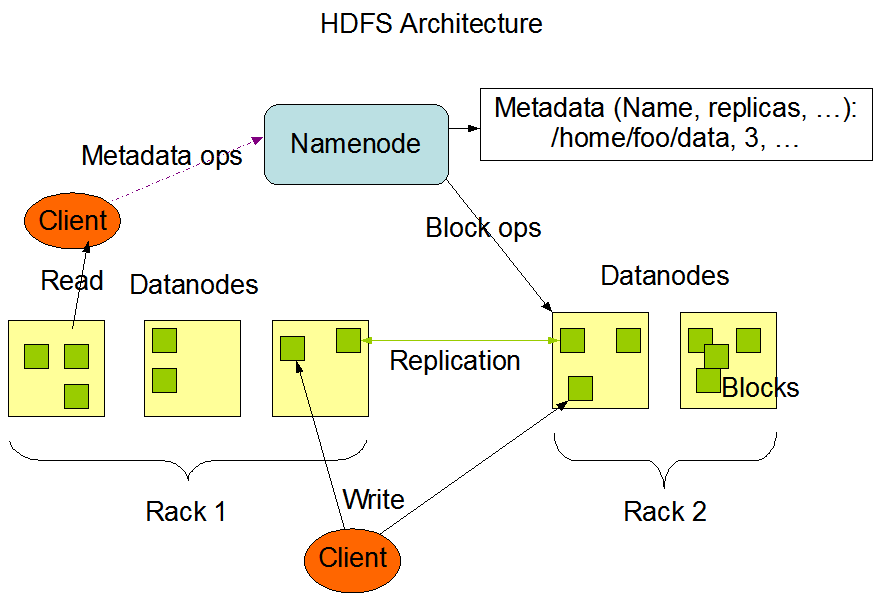
HDFS는 Hadoop Distributed File System의 약자입니다. 수십 테라바이트 또는 페타바이트 이상의 대용량 파일을 분산된 서버에 저장하고, 그 저장된 데이터를 빠르게 처리할 수 있게 하는 파일시스템입니다. 또한 저사양의 서버를 이용해서 스토리지를 구성할 수 있어 기존의 대용량파일스시스템(NAS, DAS, SAN등)에 비해 장점을 가집니다. HDFS는 블록 구조의 파일 시스템입니다. 파일을 특정크기의 블록으로 나누어 분산된 서버에 저장됩니다. 블록크기는 64MB에서 하둡2.0부터는 128M로 증가되었습니다.
네임노드와 데이터노드
HDFS는 네임노드(마스터)와 데이터노드(슬레이브)로 구현되어 있습니다. 네임노드(NameNode)는 다음과 같은 핵심기능을 수행합니다.
- 메타데이터관리 : 파일 시스템을 유지하기 위한 메타데이타를 관리
- 데이터노드 모니터링 : 데이터노드는 네임노드에게 3초마다 하트비트(heartbeat)를 전송합니다. 네임노드를 이를 이용하여 데이터노드의 실행상태와 용량을 체크합니다. 하트비트를 전송하지 않는 데이터노드는 장애서버로 판단합니다.
- 블록관리 : 장애가 발생한 데이터노드의 블록을 새로운 데이터노드에 복제합니다. 용량이 부족하다면 여유가 있는 데이터노드에 블록을 옮깁니다.
- 클라이언트 요청접수: 클라이언트가 HDFS에 접근하려면 반드시 네임노드에 먼저 접속해야 합니다. HDFS에 파일을 저장할 경우 기존 파일의 저장여부와 권한 확인 절차를 거쳐 저장을 승인합니다.
데이터노드(DataNode)는 클라이언트가 HDFS에 저장하는 파일을 로컬 디스크에 유지합니다. 이때 파일은 두가지로 저장되는데 하나는 실제 저장되는 로우데이터이고 다른 하나는 체크섬이나 파일생성일자 같은 메타데이터가 저장된 파일입니다.
MapReduce
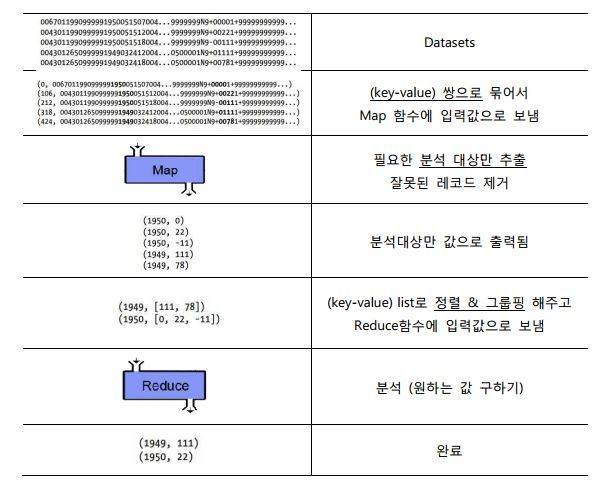
맵(map)은 흩어져 있는 데이터를 관련 있는 데이터끼리 묶는 작업을 통해서 임시 데이터 집합으로 변형되며, 리듀스(Reduce)는 맵 작업에서 생성된 임시 데이터 집합에서 중복 데이터를 제거하고 원하는 데이터를 추출하는 작업을 진행합니다. 모든 과정은 병렬적으로 진행됩니다.
V1
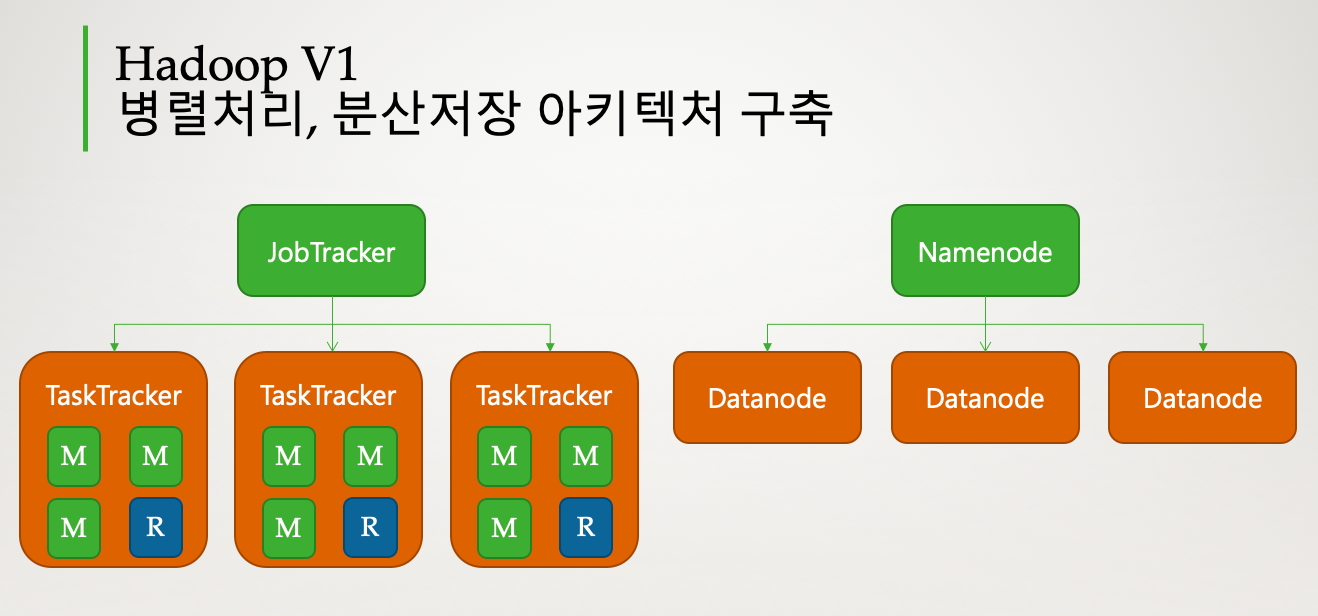
2011년에 정식 발표된 하둡 v1은 분산저장, 병렬처리 프레임워크를 정의하였습니다. 분산저장은 네임노드와 데이터노드가 처리합니다. 네임노드는 블록정보를 가지고 있는 메타데이터를 관리하고, 데이터 노드를 관리하는 역할을 합니다. 데이터노드에서 데이터를 블록단위로 나누어서 저장합니다. 블록단위 데이터는 복제하여 데이터 유실에 대비합니다.
병렬처리는 잡트래커와 태스크트래커가 처리합니다. 잡트래커가 전체 작업의 진행상황을 관리하고, 자원 관리도 처리하였습니다. 이로 인해 최대 4000대의 노드를 등록할 수 있었습니다. 태스크트래커는 실제 작업을 처리하였습니다. 병렬처리의 작업 단위는 슬롯(slot)입니다. 맵 슬롯, 리듀스 슬롯의 개수가 정해져 있고, 실행 시점에 역할이 정해지면 슬롯의 용도를 변경할 수 없기 때문에 맵 작업이 진행중에는 리듀스 슬롯은 대기상태로 있었습니다. 이로 인해 클러스터가 100% 활용되지 않을때도 있었습니다.
하둡 v1 특징
- 분산저장, 병렬처리 프레임워크를 정의
- 분산저장(HDFS)
- 네임노드, 데이터 노드가 처리
- 병렬처리(MapReduce)
- 트래커, 태스트 트래커가 처리
- 클러스터당 최대 4000개의 노드를 등록 작업 처리를 슬롯(slot) 단위로 처리 맵, 리듀스 슬롯을 구분하여 처리
V2
2012년 정식 발표된 하둡 v2는 잡트래커의 병목현상을 제거하기 위하여 YARN 아키텍처를 도입하였습니다. YARN 아키텍처는 잡트래커의 기능을 분리하여 자원관리는 리소스 매니저와 노드매니저가 담당하고, 애플리케이션의 라이프 사이클관리는 애플리케이션 마스터가 담당하고, 작업의 처리는 컨테이너가 담당합니다. 자원관리와 애플리케이션 관리의 분리를 통해 클러스터당 최대 만개의 노드를 등록할 수 있습니다.
YARN 아키텍처의 작업의 처리 단위는 컨테이너입니다. 작업에 제출되면 애플리케이션 마스터가 생성되고, 애플리케이션 마스터가 리소스 매니저에 자원을 요청하여 실제 작업을 담당하는 컨테이너를 할당받아 작업을 처리합니다. 컨테이너는 작업이 요청되면 생성되고, 작업이 완료되면 종료되기 때문에 클러스터를 효율적으로 사용할 수 있습니다.
또한 YARN 아키텍처에서는 MR로 구현된 작업이 아니어도 컨테이너를 할당 받아서 동작할 수 있기 때문에 Spark, HBase, Storm 등 다양한 컴포넌트들을 실행할 수 있습니다.
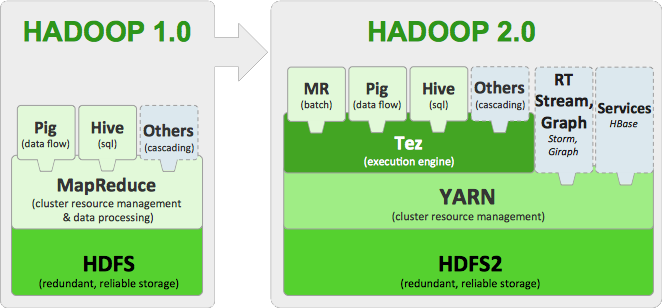
하둡 v2 특징
- YARN을 도입하여 병렬 처리 구조를 변경
- 클러스터 관리 리소스 매니저, 노드 매니저
- 작업 관리 애플리케이션 마스터, 컨테이너
- MR 외 Spark, Hive, Pig 등 다른 분산 처리 모델도 수행 가능
- 클러스터당 1만개 이상의 노드 등록 가능
- 작업 처리를 컨테이너(container) 단위로 처리
V3
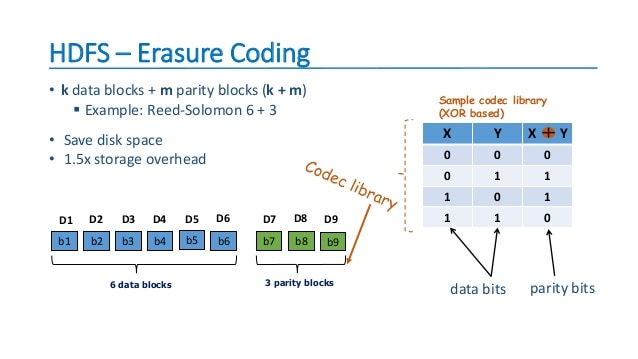
2017년 정식 발표된 하둡 v3는 이레이져 코딩, YARN 타임라인 서비스 v2 등이 도입되었습니다.
하둡 v2까지 HDFS에서 장애 복구를 위해 파일 복제를 이용했습니다. 기본 복제 단위가 3개여서, 파일 1개당 2개의 복제본을 가지게 됩니다. 이로 인해 1G데이터 저장에 3G의 저장소를 사용하였습니다. 이레이져 코딩은 패리티 블록을 이용하여 1G데이터 저장에 1.5G의 디스크를 사용하게 되고 저장소의 효율성이 증가합니다.
또한 YARN 타임라인 서버를 개선하고, 하둡 v1부터 사용하던 쉘스크립트를 다시 작성하여 버그를 해결하였습니다. 네이티브 코드를 수정하여 셔플단계의 처리 속도를 증가시키고, JAVA8을 지원하도록 수정하였습니다. 고가용성을 위하여 2개 이상의 네임노드를 지원하는 등 여러 가지 개선점이 추가되었습니다.
하둡 v3 특징
- 이레이져 코딩 도입 기존의 블록 복제(Replication)를 대체하는 방식으로 HDFS 사용량 감소
- YARN 타임라인 서비스 v2 도입 기존 타임라인 서비스보다 많은 정보를 확인 가능
- 스크립트 재작성및 이해하기 쉬운 형태로 수정
- 오래된 스크립트를 재작성하여 버그 수정
- 오브젝트 저장소 추가
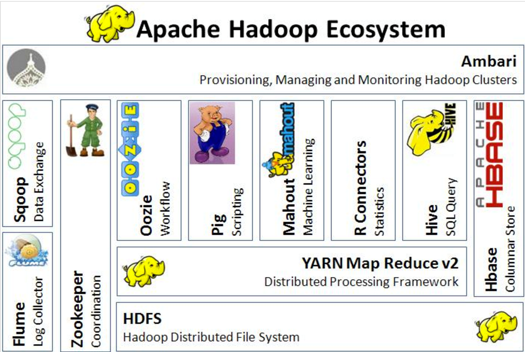
Hbase
Hadoop Echo System
Ref
https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html https://www.oracle.com/kr/big-data/what-is-big-data/ https://wikidocs.net/26170/ https://over153cm.tistory.com/entry/맵리듀스MapReduce란-1 https://velog.io/@kimdukbae/MapReduce

Comments