
Database Primary Index
RDBMS
Relational Database Management System 으로 RDB(Relation Database)를 관리하기 위한 소프트웨어이다. RDB는 관계형 데이터 모델에 기초를 둔 데이터베이스로서 2차원 테이블의 형태를 갖는다. “관계형” 데이터라는 표현은 데이터 테이블 간의 상호관련성 상관관계를 나타낸다. 테이블은 행 (row), 열(column) 으로 되어있고, 각 행은 레코드(record)로 정의한다. 이러한 테이블의 집합을 RDB라고 하며, RDB의 설계도를 ER(Entity Relationship)이라고한다. RDBMS는 RDB의 레코드들을 삽입, 탐색, 수정, 삭제하는 소프트웨어로 이러한 작업은 SQL(Structed Query Langauge)를 통해 수행한다. 이러한 관계형 데이터를 엄격하게 유지하기 위해 Transaction, ACID 라는 개념이 도입되었다. 관계형 데이터는 엄격하게 데이터를 관리하는 성격때문에, 안정성을 제공하지만 대부분의 workload가 데이터간의 일관성을 유지하는데 사용된다. 따라서 확장이 유연하지 못하고 성능에대한 고질적인 단점이 있다.
ACID
| Name | Kr | Description |
|---|---|---|
| Atomic | 원자성 | 모든 작업이 반영되거나 모두 롤백되는 특성 |
| Consistency | 일관성 | 미리 정의된 규칙에서만 수정이 가능하다. 예를들어 숫자컬럼에는 문자열을 저장할 수 없다. |
| Isolation | 고립성 | 트랜젝션 진행시 다른 트랜잭션이 개입하지 못한다. |
| Durable | 영구성 | 한번 반영된 트랜젝션의 내용은 영원히 적용된다. |
ACID를 유지하기 위해 RDBMS에서는 테이블, record를 lock 하는 것에 의존한다. NoSQL에서는 별도의 복사본을 관리하는 MVCC(multiversion concurrency control, 다중 버전 동시성제어) 방식을 사용한다.
Feature
- Database
- Table
- Index
- Clustered Index
- Secondary Index (Non-clustered index)
- Transaction
- View
- Stored Procedure
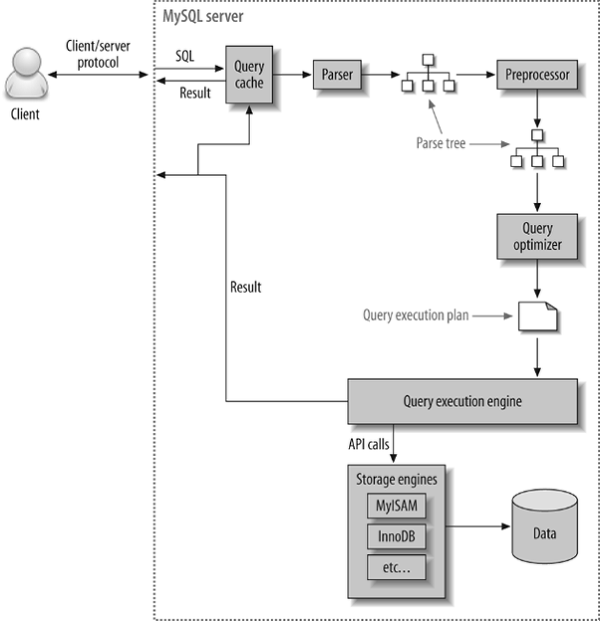
SQL의 실행과정
NoSQL
No SQL은 RDBMS 와 다른 형태를 나타내는 데이터베이스다(최근에는 데이터베이스의 한 종류를 지칭하지 않고 더 많은 것을 의미한다. 그래서 Not only SQL이라고도 한다). 고정적인 2차원 테이블외에 다른 형태의 데이터도 지원하며 대표적으로 json format과 graph format을 지원한다. 그래서 table이 아닌 document라는 명칭을 사용하기도 한다. RDBMS와 다르게 테이블간의 관계성이 비교적 모호하며 엄격하게 데이터간의 관계를 유지하지 않기때문에 유연성, 확장성, 고성능을 추구하기 위해 사용한다. 접근성능을 위해 데이터를 여러벌 복사하고, RDBMS보다 용이하게 여러개의 인스턴스에 Node를 생성하여 트래픽과 데이터를 분산하고 장애에 대응한다. RDBMS의 ACID와 대응되는 BASE 라는 개념이 도입되었다.
BASE
2000년 Eric Brewer가 “Towards Robust Distributed Systems”라는 제목으로 분산시스템의 성격을 정의할 때 명명한 내용이다.
- Basically Available : 기본적으로 Available하고
- Soft-state : 사용자가 관리(refresh, modify)하지 않으면 Data가 expire 될 수도 있으며
- Eventually consistency : 지금 당장은 아니지만 언젠가는 Data가 일관성을 가진다
- ACID와 성격을 비교하면 아래와 같다
| ACID | BASE |
|---|---|
| 중요한 commit | Avaliability 가 우선 |
| 강한 Consistency | 약한 Consistency |
| 엄격한 데이터 | 언젠가는 일관적인 데이터 |
CAP Theory
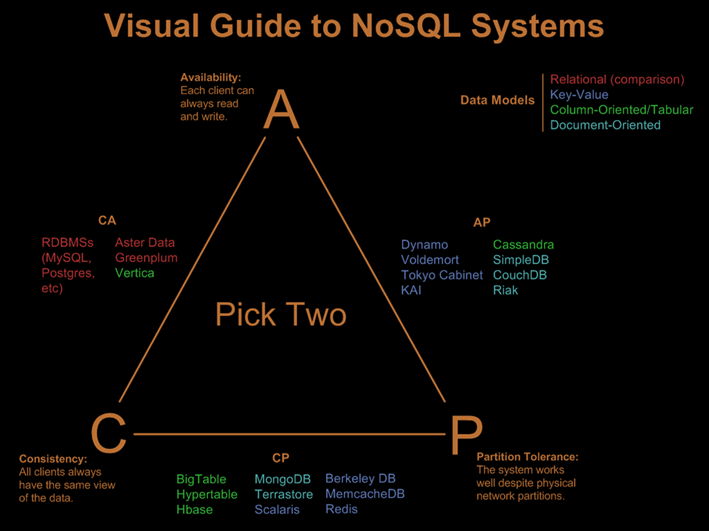
CAP이론은 “분산 시스템에서는 위 그림의 3개 속성을 모두 가지는 것이 불가능하다” 를 의미한다. C 의 정의는 Consistency 이지만 ACID의 C와는 다른 의미를 갖는다. ACID의 ‘C’는 “데이터는 항상 일관성 있는 상태를 유지해야 하고 데이터의 조작 후에도 무결성을 해치지 말아야 한다”는 속성이다. CAP의 ‘C’는 “Single request/response operation sequence”의 속성을 나타낸다. 쓰기 동작이 완료된 후 발생하는 읽기 동작은 마지막으로 쓰여진 데이터를 리턴해야 한다는 것을 의미한다.
A의 정의는 가용성 Avaliability을 의미한다. 특정 노드에 장애가 나도 서비스가 가능하다라는 의미를 갖는다.
P의 정의는 Partition Tolerance로 노드간에 통신 문제가 생겨서 메시지를 주고받지 못하는 상황이라도 동작해야 한다는 의미이다.
PACEL
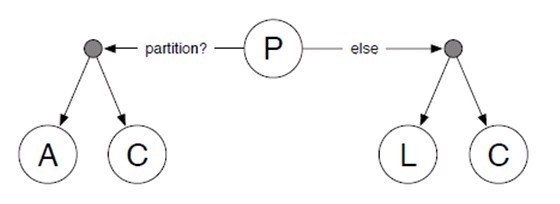
파티션(네트워크 장애)상황일 때에는 A와 C는 상충하며 둘 중 하나를 선택해야 한다. 변경된 값을 모든 노드에서 바라볼 수 있도록 하려면 신뢰성 있는 프로토콜을 이용하여 데이터에 관여하는 모든 노드에 데이터가 반영되어야 한다. 하지만 네트워크 단절이 일어나 몇 개의 노드에 접근할 수 없을 때 C를 위해 데이터 반영이 아예 실패하던지 C를 포기하고 일단 접근 가능한 노드들이게 만 데이터를 반영하던지 둘 중의 하나만 골라야 한다. 또한, 정상상황일 때에는 L과 C는 상충하며 둘 중 하나를 선택해야 한다. 모든 노드들에 새로운 데이터를 반영하는 것은 상대적으로 긴 응답시간이 필요하기 때문이다.

Comments